机器学习海报交流会_互联网舆情如何影响股市行情
互联网舆情如何影响股市行情
1. 通过tushare获取股票交易信息
以中国平安(601318.SH)为例,将获取的股票信息保存至csv文件
1
2
# 获取 601318 最近一年的交易数据(中国平安)
df = pro.daily(ts_code='601318.SH', start_date='20240329', end_date='20250329')
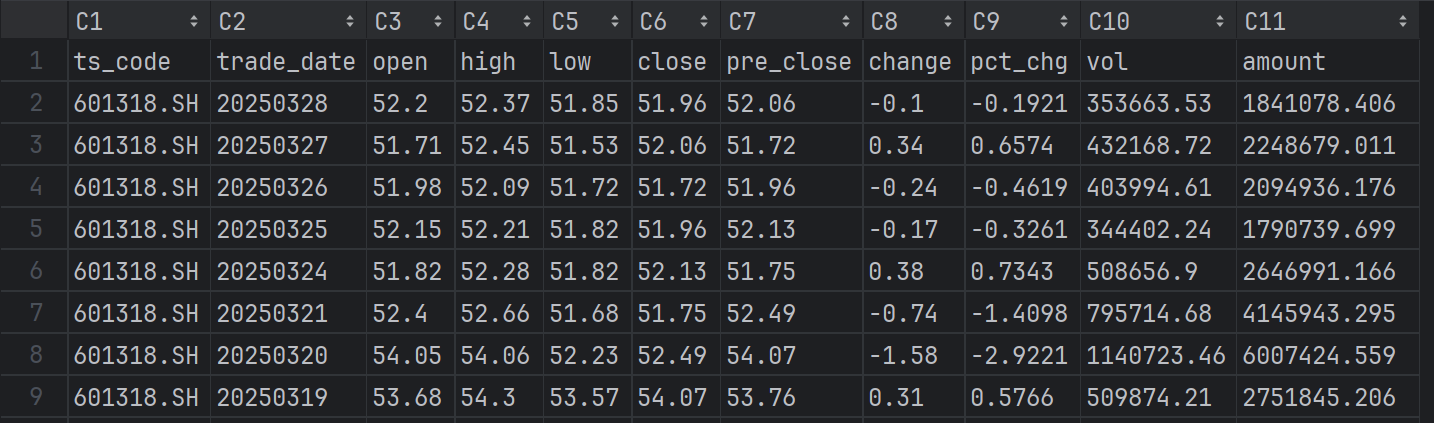
参数说明:
ts_code: 股票代码;
open, high, low, close: 开盘价,最高价,最低价,收盘价;
pre_close: 昨日收盘价;
change: close - pre_close,价格变动;
pct_chg: 当日涨跌幅,(close - pre_close)/pre_close*100%;
vol: 成交量(单位:手,每手=100股);
amount: 成交额(单位:千元)
2. 同样通过tushare获取财经新闻标题
从新浪微博、同花顺、东方财富,获取响应日期的新闻;并从中筛选标题带有“中国平安”的保存至csv(token的次数用光了,等一天后才能重试)(试完没有一条新闻包含,尝试从cctv新闻文本中获取,积分不足没有权限(放弃))
1
2
3
4
5
6
7
8
9
10
# 获取 601318 最近的交易数据(中国平安)
df = pro.daily(ts_code='601318.SH', start_date='20240329', end_date='20250329')
# news1 = pro.news(src='sina', start_date='20240329', end_date='20250329') # 新浪财经
news2 = pro.news(src='10jqka', start_date='20240329', end_date='20250329') # 同花顺
# news3 = pro.news(src='eastmoney', start_date='20240329', end_date='20250329') # 东方财富
news = pd.concat([news2],ignore_index=True)
news_filt = news[news['title'].str.contains("中国平安",na=False)]
print(news_filt.head())
1
2
3
4
# 从cctv过去包含对应文本的代码也在此给出
cctv_news = pro.cctv_news(start_date = '20240329',end_date = '20250329')
filt_cctv = cctv_news[cctv_news['content'].str.contains(r"中国平安|平安|601318", na=False, regex=True)]
print(filt_cctv.head())
后面的分析均假设成功获取相应文本的基础上进行
3. 使用SnowNLP进行情感分析
注:SnowNLP是基于朴素贝叶斯的情感分析工具,在商品购买领域效果较好,可能在财经领域表现一般
1
2
3
4
# 例
text = "中国平安股票今日大涨,投资者信心十足!"
s = SnowNLP(text)
print(s.sentiments) # 0.9995795141082536, 越接近1越积极
4. 将股票数据和情感得分数据按照日期合并
5. 使用决策树进行分析
选择特征,定义标签:1涨,0跌
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 简单决策树,由于没有数据,无法进行调参
# 读取合并后的数据
data = pd.read_csv("final_stock_sentiment_data.csv")
# 选择特征和目标变量
features = ['open', 'high', 'low', 'vol', 'sentiment_score', 'sentiment_3d_avg', 'sentiment_7d_avg']
X = data[features]
y = data['label'] # 1 涨,0 跌
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练决策树模型,设置最大深度
model = DecisionTreeClassifier(max_depth=5)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率: {accuracy:.4f}")
import matplotlib.pyplot as plt
feature_importance = model.feature_importances_
plt.barh(features, feature_importance)
plt.xlabel("Feature Importance")
plt.ylabel("Feature Name")
plt.title("基于舆情的股票分析")
plt.show()
6. 使用SVM进行分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, classification_report
# 读取合并后的数据
data = pd.read_csv("final_stock_sentiment_data.csv")
# 选择特征和目标变量
features = ['open', 'high', 'low', 'vol', 'sentiment_score', 'sentiment_3d_avg', 'sentiment_7d_avg']
X = data[features]
y = data['label'] # 1 涨,0 跌
# 归一化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 训练 SVM 模型
svm_model = SVC(kernel='rbf', C=1.0, gamma='scale') # 高斯核
svm_model.fit(X_train, y_train)
# 预测
y_pred = svm_model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"SVM 模型准确率: {accuracy:.4f}")
# 输出详细分类报告
print(classification_report(y_test, y_pred))
后续可以使用GridSearchCV进行超参数调优
7. 现有资料查询
https://pdf.hanspub.org/aam20221100000_79882519.pdf
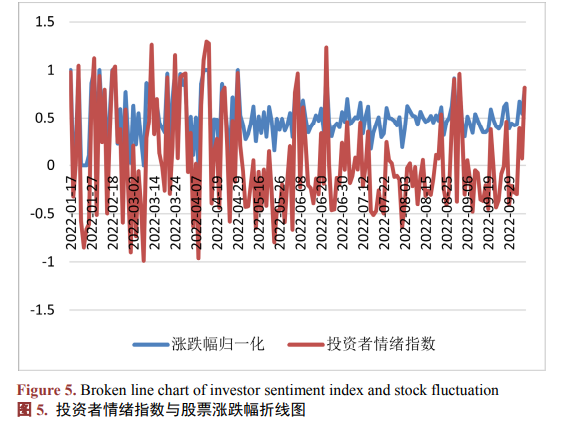
从较长期来看,股吧评论的情感倾向对股票涨跌幅具有负向预测作用;
该结果可由“羊群效应”解释,长期情绪会被投资者放大,导致认知偏差,做出错误投资决策,影响股价涨跌幅,导致收益率降低
https://wxysjxb.ajcass.com/Admin/UploadFile/Issue/r5wvt0xc.pdf
- 正面舆情:微博网络舆情受到关注力度增高,随着时间推移,舆情评论数量减少,关注度逐渐降低;
- 负面舆情:评论和舆论的关注度则会随着舆情演化发展的时间不断增加,直至股价回升
This post is licensed under CC BY 4.0 by the author.