心音疾病诊断 —— 二分类子模型训练
心音疾病诊断 —— 二分类子模型训练
1. 音频分类模型:facebook/wav2vec2-base
模型链接:https://huggingface.co/facebook/wav2vec2-base
- 不冻结任何层,修改其分类头结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Wav2Vec2Classifier(nn.Module):
def __init__(self):
super().__init__()
self.wav2vec2 = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base")
self.classifier = nn.Sequential(
nn.Linear(768, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 128),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Dropout(0.3),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, input_values):
out = self.wav2vec2(input_values).last_hidden_state
pooled = out.mean(dim=1)
return self.classifier(pooled).squeeze(1)
- 损失函数:BCELoss
- 训练策略:
- 优化器:AdamW
- 学习率:主干1e-4, 分类头3.5e-4
- 学习率策略:get_cosine_shedule_with_warmup, 预热步数为20%
- batch size = 16
- 训练轮数: 5
- 保存验证集损失最低的模型
分类正确率:88.55%
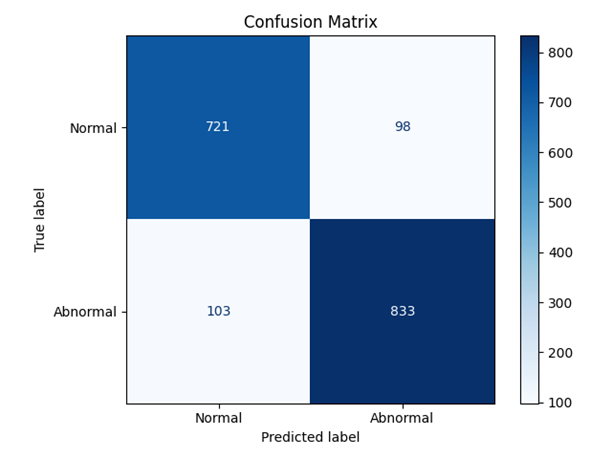
2. 音频分类模型:facebook/hubert-base-ls960
模型链接:https://huggingface.co/facebook/hubert-base-ls960
不冻结任何层,同样修改其分类头结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
class HuBERTClassifier(nn.Module): def __init__(self): super().__init__() self.hubert = HubertModel.from_pretrained("facebook/hubert-base-ls960") self.classifier = nn.Sequential( nn.Linear(self.hubert.config.hidden_size, 512), nn.ReLU(), nn.BatchNorm1d(512), nn.Dropout(0.5), nn.Linear(512, 128), nn.ReLU(), nn.BatchNorm1d(128), nn.Dropout(0.3), nn.Linear(128, 1), nn.Sigmoid() ) def forward(self, x): out = self.hubert(x).last_hidden_state pooled = out.mean(dim=1) return self.classifier(pooled).squeeze(1)
损失函数:BCELoss
训练策略:
- 优化器:AdamW
- 学习率:主干1e-5, 分类头3.5e-4
- 学习率策略:get_cosine_schedule_with_warmup, 预热步数20%
- batch size = 16
- 训练轮数:5
- 保存验证集损失最低的模型
分类正确率:89.46%
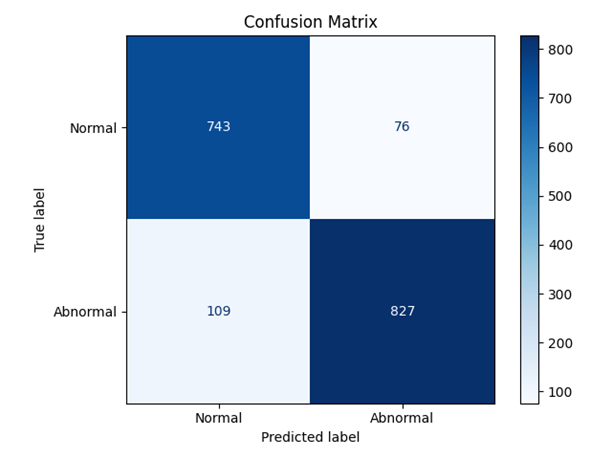
3. 图像分类模型:convnext_tiny
图像数据增强处理:
1 2 3 4 5 6 7 8 9 10
train_transform = transforms.Compose([ transforms.Resize((224, 224)), # 统一大小 transforms.RandomHorizontalFlip(), # 水平方向随机翻转 transforms.ColorJitter(brightness=0.2, contrast=0.2), # 颜色抖动 transforms.RandomRotation(degrees=3), # 轻微旋转 RandomCLANE(p=0.4, mask_ratio=0.25), # 对图像的判别性区域进行掩码擦除 transforms.ToTensor(), transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), transforms.RandomErasing(p=0.1) # 随机擦除 ])
调整模型输出类别为2:
1
model = create_model("convnext_tiny", pretrained=True, num_classes=NUM_CLASSES)
损失函数:带标签平滑和类别权重的交叉熵损失函数,由于在训练过程中发现健康样本比较难区分,因此提高健康样本的权重
1
criterion = nn.CrossEntropyLoss(label_smoothing=0.1, weight=torch.tensor([1.1, 0.9]).to(DEVICE))
训练策略:
- 优化器:AdamW
- 学习率:主干1e-5, 头部3.5e-4
- 学习率策略:get_cosine_schedule_with_warmup, 预热步数20%
- batch size = 64
- 训练轮数:30
- 保存验证集损失最低的模型
分类正确率:87.07%
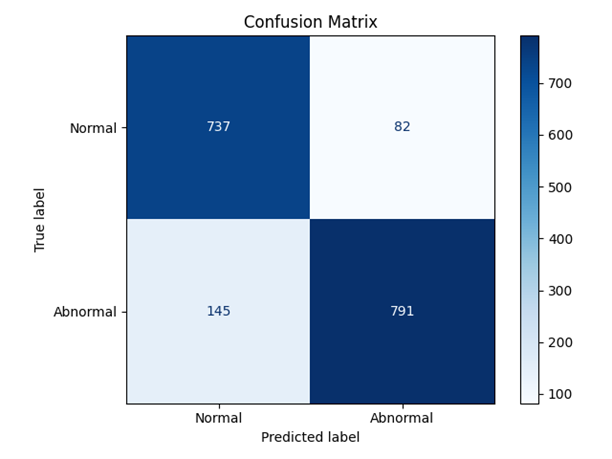
This post is licensed under CC BY 4.0 by the author.