模型集成 —— LightGBM及相关方法介绍
1. Gradient Boost(梯度提升)
讲解视频:https://youtu.be/3CC4N4z3GJc?si=MTAW7mrh7sNhzRbO
与AdaBoost的对比:
AdaBoost: https://hhhi21g.github.io/posts/%E8%AF%BE%E7%A8%8B9%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0/#adaboost%E7%AE%97%E6%B3%95
- AdaBoost初始时即有stump(树桩),但也只有树桩;
- Gradient Boost(for Regression)初始时只有一个点,为连续值的均值;对于树来说比AdaBoost的树桩大,可以限制最大叶子结点个数,通常为8到32。
是一种通用的集成学习框架,属于Boosting系列。常见的Gradient Boosting实现有:GBDT, XGBoost,LightGBM,CatBoost.
Gradient Boost For Regression
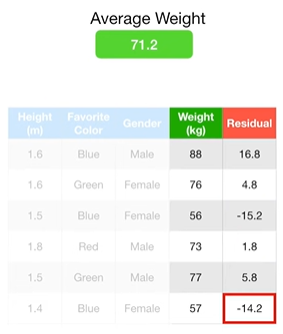
先计算连续值的均值,再计算伪残差:如上图,先计算Weight的均值,再逐一相减;
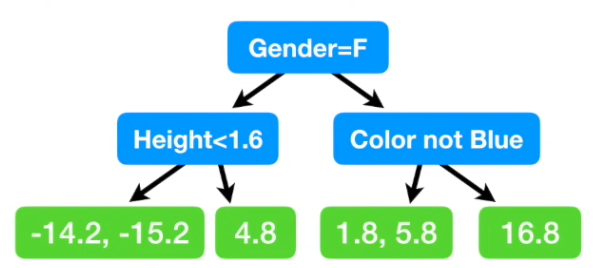
建立一棵树,由Height, Favorite Color, Gender 预测 Residual;(限制最大叶子结点数目为4);
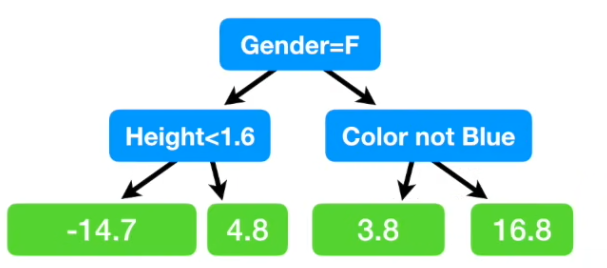
最终到同一叶子结点的数据,在上图中即第1、3叶子,对数值取均值,(-14.2 - 15.2)/2 = -14.7, (1.8 + 5.8)/2 = 3.8;

根据其他特征,找到树中对应的叶子结点,用初始树桩值与该叶子结点值相加即为预测值。
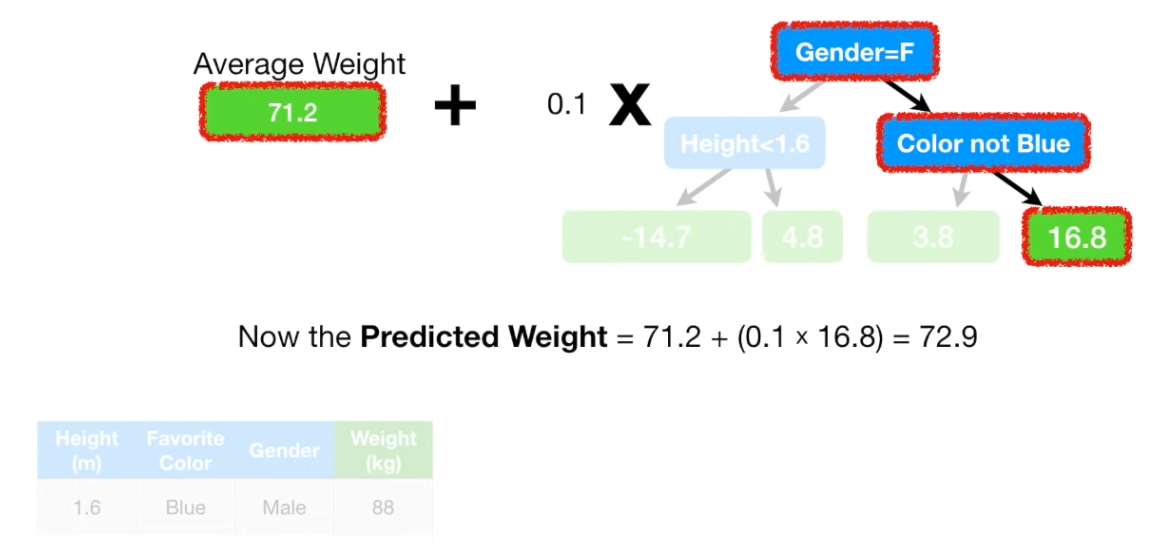
问题:拟合的太完美了? —— 使用学习率

重复上述步骤:计算每个数据的根据树得到的值,再次与原始值做差,得到新残差;
再次计算时,需要将两个树都计算进来;
2. XGBoost
XGBoost For Regression
XGBoost was designed to be used with large, complicated data sets.
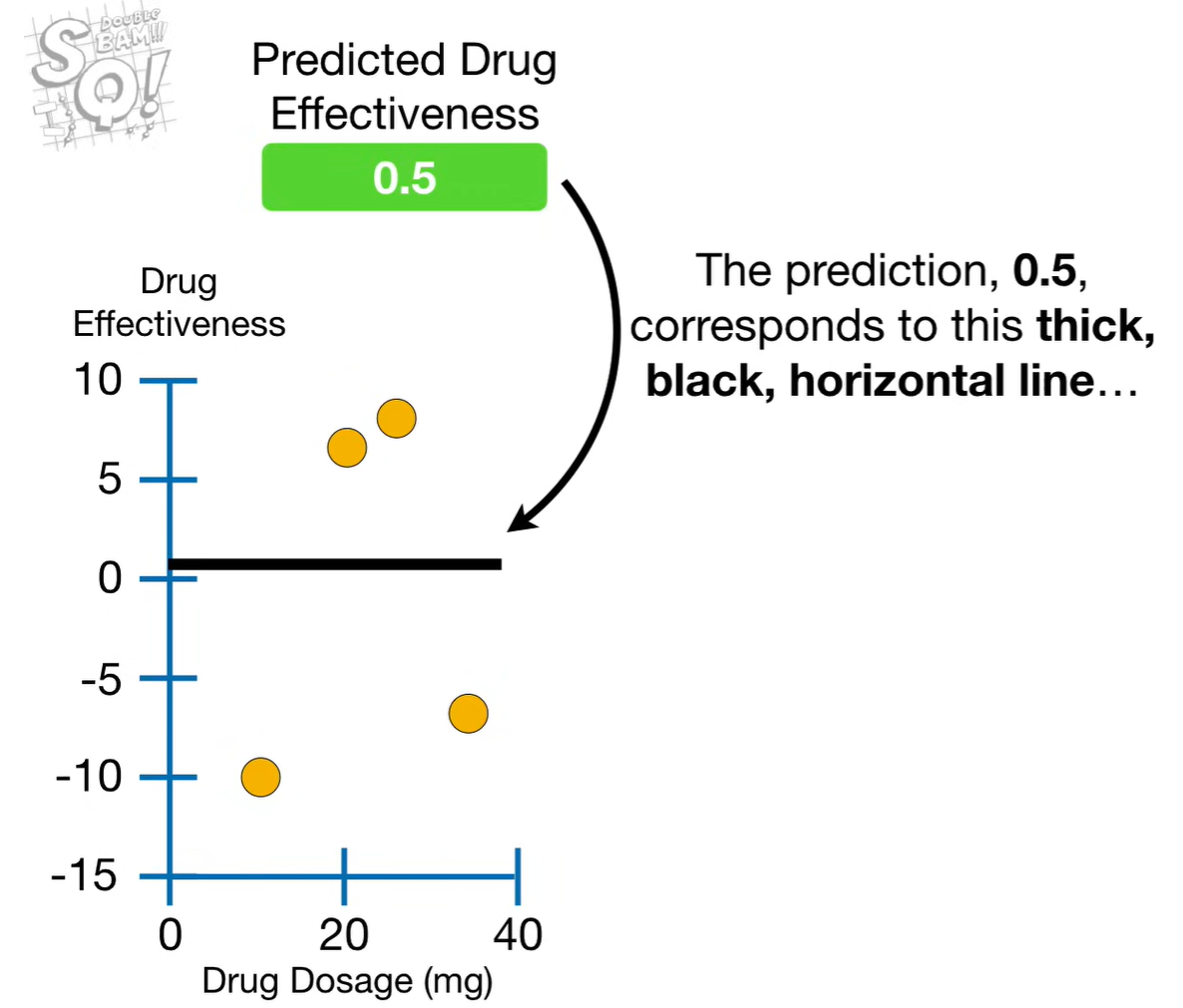
最开始给出预测值,该预测值可以为任何值,但默认为0.5;
计算所有数据点与该预测值的残差;
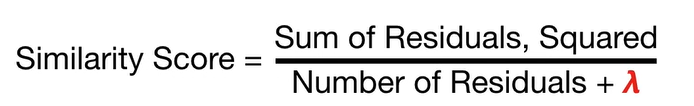
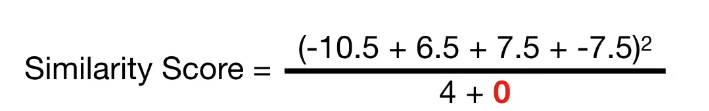
如上图,计算Similarity Score, 暂将λ(正则项)设置为0;
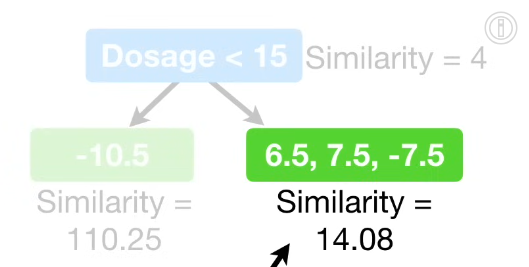
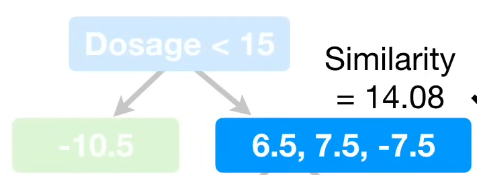
以两相邻点的中值为划分点,第一次划分即为:以Dosage10和Dosage20中点,即Dosage=15进行划分,若小于15,则划分至左节点;否则,则划分至右节点。同上,分别计算两个叶子节点的Similarity(计算similarity score时,如果两个数据点残差一正一负,则得分会被抵消而较小;如果两个数据点残差符号相同,无法抵消,则残差会非常大);
Gain = Leftsimilarity + Rightsimilarity - Rootsimilarity , 该例中即110.25 + 14.08 - 4 = 120.33;
重复上述计算Gain步骤,分别计算3个划分点得到的Gain值,选择Gain最大的一个作为划分点(本例中为15);
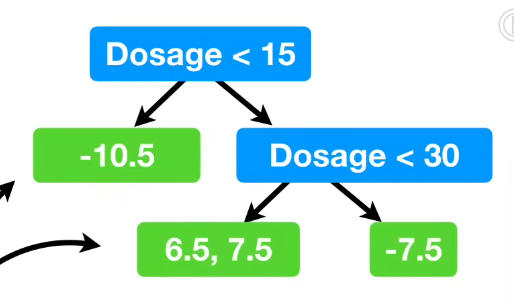
对能够划分的节点继续划分, 这里限制树的最大深度为2;
剪枝操作:基于Gain。选择一个数字,例如130(gamma,γ)。如果Gain - γ > 0, 不进行剪枝;小于0则进行剪枝(令γ=0并不会停止剪枝);
λ说明:设置lambda=1而非0,能够避免过拟合训练数据;
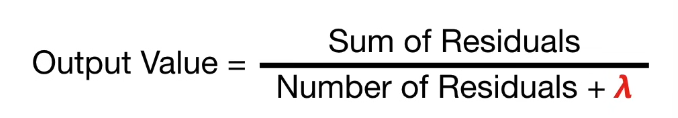
XGBoost树的输出;
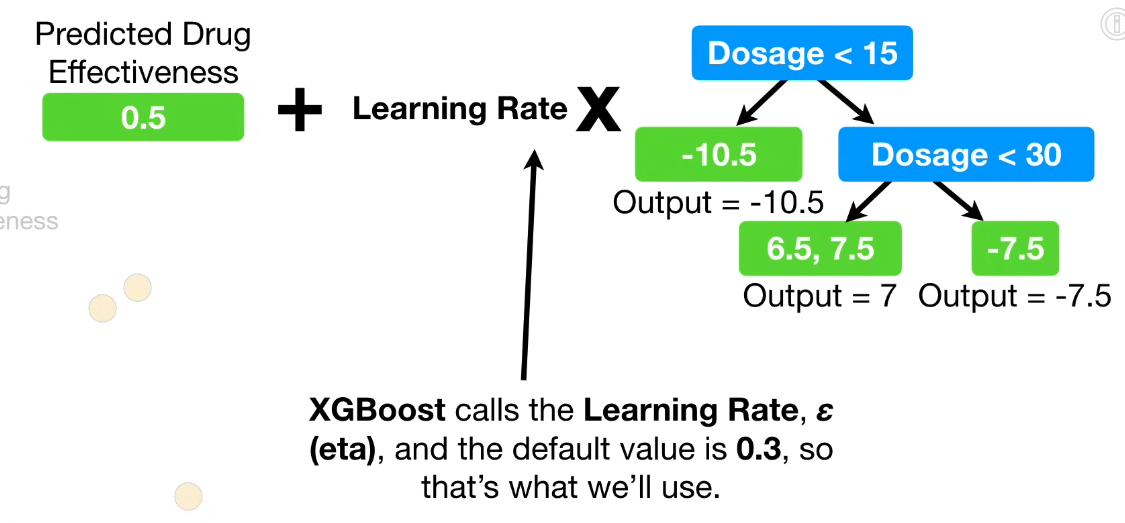
对新数据的预测,类似Gradient Boost, 使用学习率eta;
3. LightGBM
LightGBM is a type of gradient boosting machine(GBM), which combines multiple weak learns(usually decision trees) to create a strong predictive model.
把多个基础模型的输出再喂给一个二层模型,即让它学习“什么时候更信某个模型”的规律,从而比简单平均更准。
输入:各基模型对同一样本的概率;
输出:融合后的最终概率或标签。
Stacking: 用(OOF, Out-Of-Fold)方式生产二层训练集,严格避免信息泄露,+