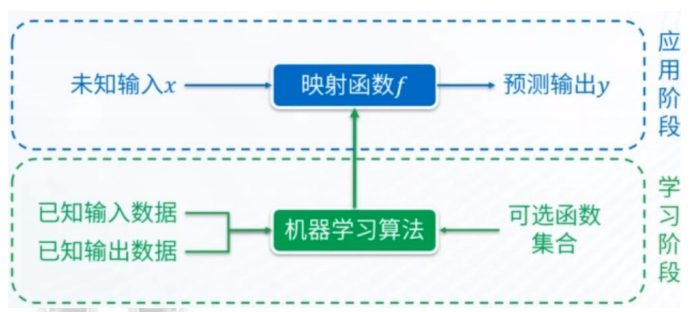
机器学习第1讲——机器学习方法概论
机器学习第1讲——机器学习方法概论
分类
有无标记信息:
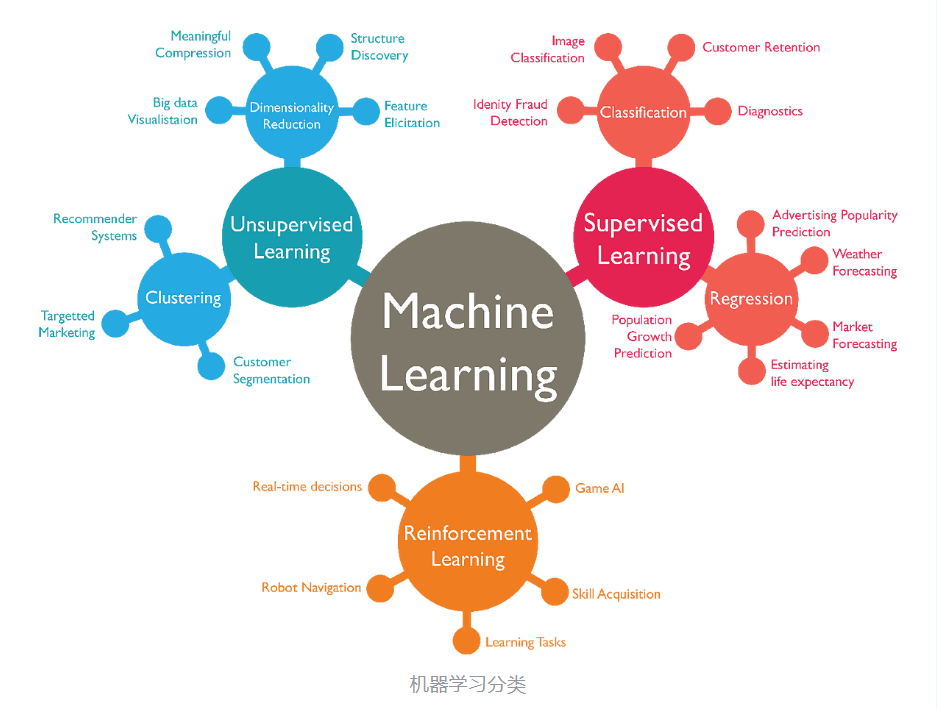
- 监督学习(Supervised Learning):分类、回归;
- 无监督学习(Unsupervised Learning):聚类(Clustering)、关联(Association)、降维(Dimensionality Reduction);
- 半监督学习(Semi-supervised Learning):两者结合,只标记数据集中的一部分,而不是标记整个数据集。
强化学习(Reinforcement Learning):没有答案,但是有奖励/惩罚信号,探索学习。
自监督学习(self-supervised Learning, SSL):不需要人工标注训练数据,主要训练从大规模的无监督数据中挖掘能够应用于自身的监督信息,从而从输入的一部分数据中去学习另一部分。
基本术语
- 分类
回归:根据观测数据预测对象的某个连续属性的数值;
聚类: 将观测数据分为由相似对象组成的多个类别;
生成模型(Generative Model):学习数据的分布,即通过建模数据的生成过程来理解数据的本质;
试图学习联合概率分布P(X,Y), X是输入,Y是目标(图像,文字,视频);
- 判别模型(Discriminative Model):直接学习输入特征X和目标标签Y之间的映射关系,即学习条件概率分布P(Y|X)
来自GPT观点:高斯混合模型(GMM)是生成模型;其他聚类既不是生成也不是判别。
- 异常检测:找出不属于某个类别的异常对象。
机器学习三要素:模型+策略+方法(PPT-6)
正则化技术
为防止过拟合,为损失函数加上一个惩罚项,对复杂的模型进行惩罚,强制让模型的参数值尽可能小以使得模型更简单,以提高泛化能力。
范数:用来表征向量空间中的距离
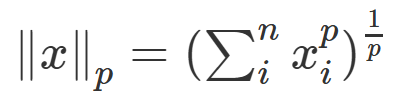
- p=1, L1范数,某个向量所有元素绝对值之和;
- p=2, L2范数,平方和再开根。
常用正则——L2正则化
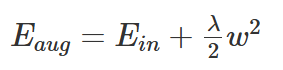
常用正则——L1正则化
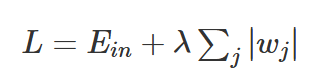
详情:https://www.cnblogs.com/liuxiaochong/p/14253397.html
评估方法
- 留出法:
- 直接将数据集划分为两个互斥集合;
- 训练、测试集要尽可能保持数据分布的一致性;
- 若干次随机划分,重复实验求均值;
- 训练: 测试通常为2 : 1 ~ 4 : 1。
- 交叉验证法:
- 数据集采样划分为k个大小相似的互斥子集;
- 每次用k-1个子集的并集作为训练集,余下子集作为测试集;
- 最终返回k个测试结果的均值。
- 自助法(数据集少):
- 对数据集D有放回采样m次得到训练集D’ ,D - D’用作测试集;(假设数据集有m个样本)
- 约有1/3的样本没在训练集中出现(1/e);
- 对集成学习有很大好处;在数据集较小,难以有效划分训练/测试集时很有用;
- 改变了数据集分布可能引入估计偏差,在数据量足够时,其他方法更常用。
性能度量
回归任务——均方误差:
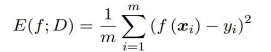
分类任务——错误率 & 精度:
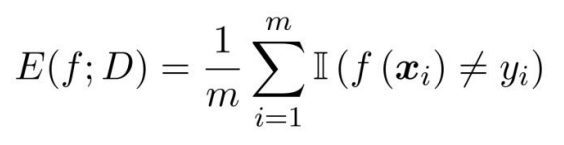
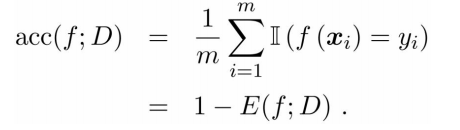
查准率-查全率曲线(P-R曲线):
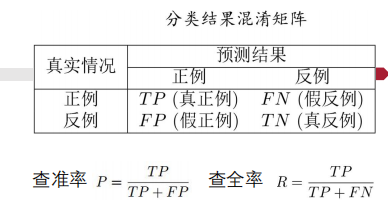
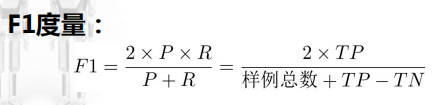
注意:二分类计算时,以一个样本的预测值为阈值,则该样本预测结果为正。
ROC曲线:以假正例率为横轴,真正例率为纵轴(受试者工作特征曲线)
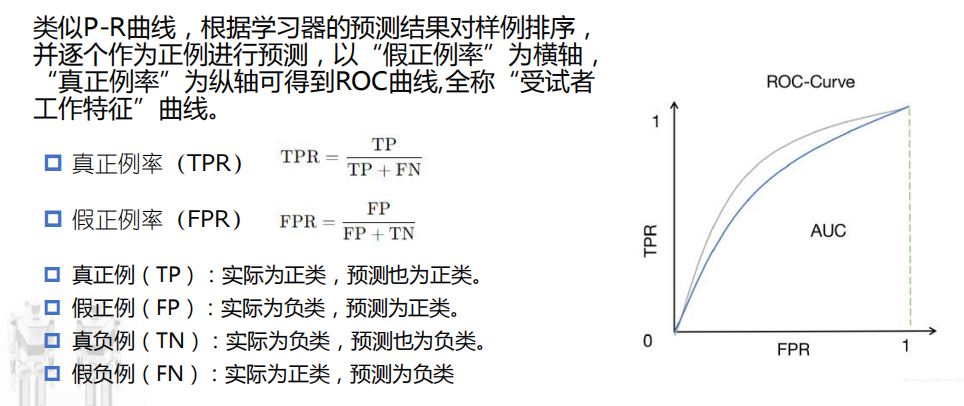
AUC:衡量样本预测的排序质量。排序质量是指模型将正类样本排在父类样本前面的能力。
AUC计算方式:https://blog.csdn.net/qq_43799400/article/details/135540298
别看PPT
统计假设检验
t检验复习

PPT例题P23页,并没有n-1,而是直接使用n??

其余检验(暂略)
一些碎片
- 深度学习:通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
- ChatGPT基本原理是引入新技术RLHF(Reinforcement Learning with Human Feedback,即基于人类反馈的强化学习)。GPT构建了海量自然语言和代码的概率分布空间,被注入足够的信息量(等于注入大量负的信息熵),形成各种复杂关联的模式,涵盖自然语言和代码中各种知识与结构。这些知识和结构,体现为概率分布的距离与关系,从而为对比、类比、归纳、演绎等推理步骤提供支撑,也就是涌现出这些推理能力。
This post is licensed under CC BY 4.0 by the author.