01_Repeated Padding for Sequential Recommendation
来源:RecSys’24 https://doi.org/10.1145/3640457.3688110
数据集及代码:https://github.com/KingGugu/RepPad
问题的引出
训练过程,长序列被截断,短序列被填充
由于用户习惯和长尾效应,只有少数用户有长的交互序列,大多数用户的交互序列非常短
当填充一个序列,0经常被使用,它不包含任何有意义的信息并且不被包括在模型计算,引出问题:我们能否通过填充其他内容来利用这个空闲空间以进一步提高模型表现和训练效率?
Can we utilize this idle input space by padding other content to improve model performance and training efficiency further?
提出一个填充策略:Repeated Padding (RepPad)
问题符号化
user sets: 𝒰
item sets: 𝒱
Each user u∈𝒰 is associated with a sequence of interacted items in chronological(按时间前后顺序排列的) order su = [v1,…,vj,…v|su|]
- vj : user u 与该物体交互在时间步长为j时
- |su| : 序列长度
给出交互物体序列|su|, 任务是正确的预测: 用户u在时间步长为|su|+1时最可能交互的物体v*
Given the sequences of interacted items 𝑠𝑢 , our task is to accurately predict the most possible item 𝑣 ∗ that user 𝑢 will interact with at time step |𝑠𝑢 | + 1
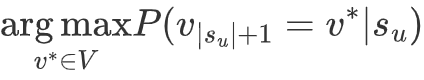
相关的现有技术
Padding in Sequential Recommendation
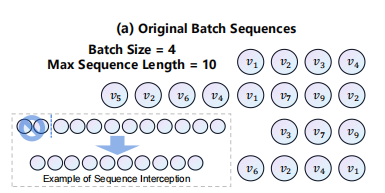


ZeroPad(·) : padding the 0 to the left side of the sequence until its length is N
Intercept(·) : intercepting the nearest N interactions
sfu : the final input to the model where |sfu | = N
|𝒰| : the total number of sequences involved in model training, one sequence for each user
N : 最大序列长度
Sequence Data Augmentation

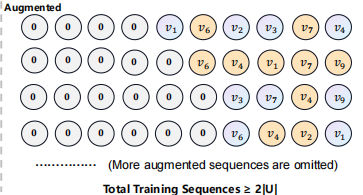
To alleviate the data sparsity problem
sdu : the new sequence , 与 su都用于模型训练和自我监督学习
- 在每一轮,每个序列都将被扩张至少一次,因此包括在模型训练中的序列数目至少为2|𝒰|
- 原始序列和增强后的序列同样需要应用(2)式
RepPad
利用原始序列作为填充文本,而不是0
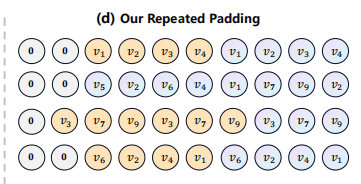
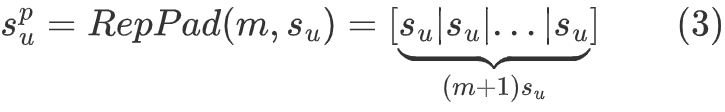
m :
填充次数
can be pre-specified or calculated based on the original sequence length su and the maximum sequence length N
problem: there may be cases where the end of the original sequence is used to predict the head
可能错误的使用尾部去预测头部:以第一个序列为例,可能错误的引入v4到v1这一序列,但实际并不存在这个关系,因此使用0当作重复的分隔符。

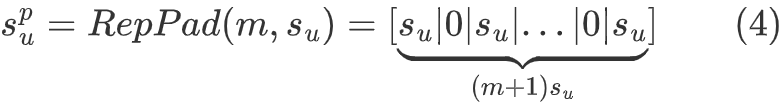
特点:
没有可训练的参数或超参数
是一种与模型无关的即插即用的数据增强方法
It is a model-agnostic plug-and-play data augmentation approach
不受主干网络的限制,并可以无缝插入到大多数现有的序列推荐模型中
使模型能够公平的关注短序列和长序列,更关注长尾项目和用户。模型可以更好的学习冷启动用户和项目的表现。
推测,起到了某种正则化的作用,减轻了原始数据集分布不均匀的消极影响
We also speculate that RepPad acts as some kind of regularization, which mitigates the negative effects of the uneven distribution of original dataset.
Why RepPad works?
损失收敛和训练效率
RepPad损失收敛速度比原始模型略快,且仅增加了少量耗时
梯度稳定性
梯度稳定性研究表明,更稳定或平滑的梯度更有助于模型训练;使用该方法后,梯度值更加稳定
与现有方法的比较:
不会增加序列数目
没有超参数
无需训练成本,与模型无关
No Training Cost and Model Agnostic.
局限:
Intuitively, 可能是无效的在长序列数据集上;
因为对于长序列数据集,大多数使用者的序列长度接近或超过所给的最大序列长度,将没有空间留给填充。
实验
the baselines consisit of three main catagories:
去评价RepPad是否在提高模型的表现方面是有效的
- 被广泛使用的随机数据增强方法,不需要训练但是包括一些需要手动调优的超参数
- 训练所需的数据增强模型代表,通常包含可训练的参数和超参数
评价指标(Evaluation Metrics):
留一法策略(Leave-one-out strategy)
测试数据:用户序列的最后一个项目
验证数据(validation data): 倒数第二个项目
训练数据:剩余的数据
we adopt the leave-one-out strategy, wherein the last item of each user sequence serves as the test data, the items preceding it as validation data, and the remaining data as training data.
预测时对全体候选物品集合进行排序,而不是仅对负样本采样
负采样可能会导致评价结果偏差
具体指标:
- HR@K:Hit Ratio@K,命中率,测试物品是否出现在预测结果的前K位,存在则计1,否则计0。反映“是否推荐成功”。
- NDCG@K: Normalized Discounted Cumulative Gain@K,归一化折损累计增益,考虑测试物品在推荐列表中的排名位置,排名越靠前得分越高。反应“推荐质量”。
消融实验(Ablation Study)
注:消融研究通常是指通过逐步移除或修改模型中的某些组件,来观察这些变化对模型性能的影响,从而理解各个组件的作用。
- RP-Fix: 固定次数,测试1、2、3次,取最好结果
- RP-Max:填充直至剩余空间不充足
- RP(0,Max):每次填充随机选择0到最大次数
- RP(1,Max):每次填充随机选择1到最大次数
3,4表现较好,1,2提升有限甚至可能导致性能下降
且4更好,说明至少填充一次是必要的。
是否填充0?
与推荐模型的类型相关:RNN不加,Transformer加
推测:Transformer为基础的模型的自注意力机制需要考虑每个历史交互的影响,0可能减少“用头部预测尾部”的负面影响。
The self-attention module of Transformer-based models pays attention to the effect of each historical interaction on the following action, so the negative effect of “predicting the tail with the head” can be minimized by adding the delimiter 0.