02_Augmenting Sequential Recommendation with Balanced Relevance and Diversity
来源: AAAI‘25 https://doi.org/10.48550/arXiv.2412.08300
代码:https://github.com/KingGugu/BASRec.
问题的引出
增强数据的相关性和多样性之间的不平衡仍需要解决;
直接合并两个增强序列将会破坏原始序列模式,并且不相关或重复的项将会被保存;
现有的方法缺少对跨序列偏好模式和语义信息的注重;
lack consideration for the cross-sequence preference patterns and semantic information.
提出BASRec, Balanced data Augmentation plugin for Sequential Recommendation
准备工作
问题符号化
user sets: 𝒰
item sets: 𝒱
Each user u∈𝒰 is associated with a sequence of interacted items in chronological(按时间前后顺序排列的) order su = [v1,…,vj,…v|su|]
- vj : user u 与该物体交互在时间步长为j时
- |su| : 序列长度
给出交互物体序列|su|, 任务是正确的预测: 用户u在时间步长为|su|+1时最可能交互的物体v*
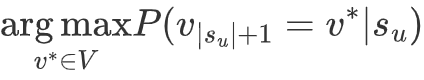
用于数据增强的混合(Mixup for Data Augmentation)
在输入空间中实现线性插值来构建虚拟训练数据
It implements linear interpolation in the input space to construct virtual training data.
给出两个输入样本xi,xj,以及标签yi,yj,混合过程如下:
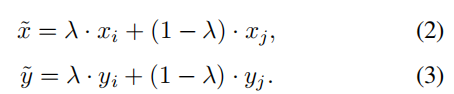
λ ∼ Beta(α, α)为beta分布中的混合参数
beta分布:
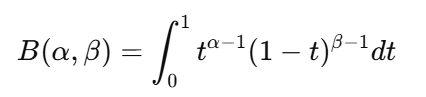
其取值范围为(0,1),所以它经常用于表示概率或系数的权重,比如在Mixup里决定两个样本的混合比例。
在Mixup数据增强中:
- α = 1时,λ服从均匀分布,即Mixup随机选择两种数据的权重;
- α > 1时,λ更接近0.5,表示生成的数据更加均匀地融合了两个样本的信息;
- α < 1时,λ可能非常接近0或1,表示生成的数据更接近其中一个原始样本
BASRec
下面两个增强模块是独立的增强路径,即通过单序列增强生成的序列表示不会被fed into跨序列增强中。
1. Single-sequence Augmentation
Look-up操作:给定原始的用户交互序列 su=[v1,v2,…,v|su|], 通过Look-up操作从物体嵌入矩阵中获取该序列对应的物品嵌入表示: Eu=[mv1,mv2,…,mv|su|];
省略对短序列的填充和对长序列的截断;
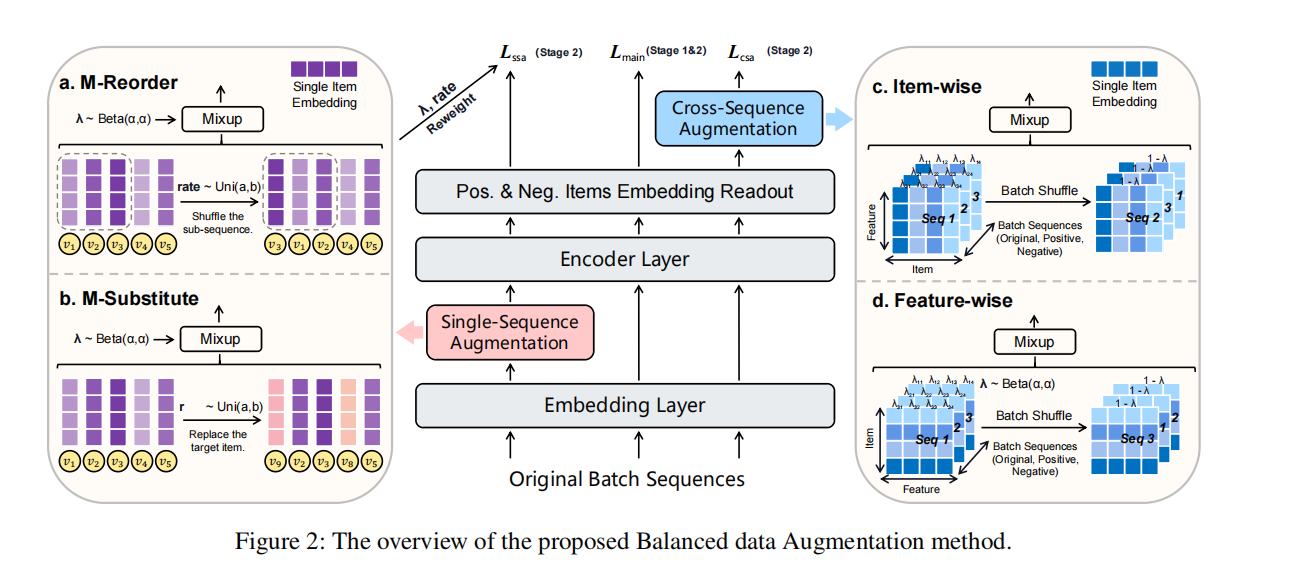
(1) M-Reorder:
- 选择子序列(sub-sequence)长度: length c = rate · |su|
不像传统操作那样使用一个固定不变的rate, 这里rate从均匀分布(Uniform distribution)中选取:
rate ~ Uniform(a,b)。a,b为超参数,且0<a<b<1
随机打乱子序列:
[vi , … , vi+c-1]打乱为[vi’ , … vi+c-1’] ,再与子序列外的项拼接得到:
su’ = Record(su) = [v1 , v2 , … vi’ , … vi+c-1’ … ,vn]
混合序列:
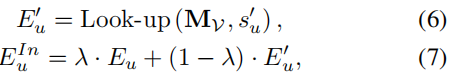
EuIn is augment representation used for model training.
(2) M-Substitute
随机选取c = rate · |su| different indices {idx1, idx2, ….. ,idxc}, rate选取方式同M-Recorder;
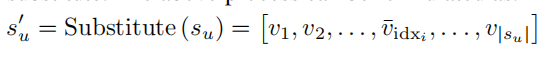
- 再进行M-Recorder中的混合序列操作,得到EuIn。
(3) 自适应损失加权(Adaptive Loss Weighting)
计算初始加权:
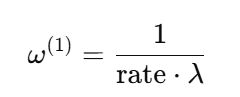
对w(1)进行归一化:
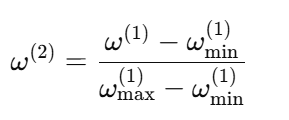
输出加权w = w(2),并为每个增强后的表示Euf分配一个独立的权重;
这个过程能够指导模型辨别原始表示中被注入了多少新的表示,提高模型的鲁棒性。
2. Cross-sequence Augmentaion
跨序列增强通过混合不同的序列输出,以发现不同用户之间的偏好知识。
将序列表示Eu和EuIn输入到编码器,获得序列的输出表示Hu和HuIn;
推荐系统中,用户表示通常是隐式的,因此Hu和HuIn也可以看作用户表示;
这里想要应用不同的权重给Hu里的每一个参数,但是,这种混合策略会造成显著的计算开销;
因此提出一种分解这个过程的方式,分解为:Item-wise mixup和Feature-wise mixup
具体实现:
- 给出一组序列{su}u=1B,能够获得相应的表示{Hu}u=1B ∈ RB * N * D, (B: 批量大小;N:最大序列长度;D:嵌入维度)
从批处理的视角洗牌Hu: {H’u}u=1B = Shuffle{Hu}u=1B
For Item-wise Nonlinear Mixup:
从Beta(α, α)中抽取一个混合的权重矩阵 ΛI∈RB*N ,混合操作如下(Hadamard product):
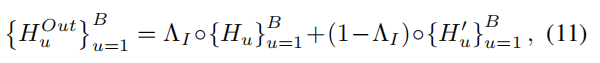
For Feature-wise Nonlinear Mixup:
从Beta(α, α)中抽取一个混合的权重矩阵 ΛF∈RB*N,作相似操作:
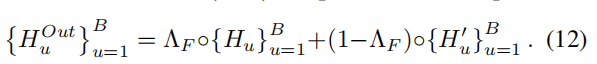
模型训练
BCE(binary cross-entropy)
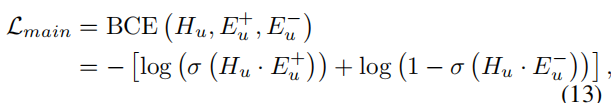
Hu, Eu+, Eu-: the user, the positive and negative items. σ(): the sigmoid function
Lmain中的表示不会被增强;
对于每个序列,我们应用两个算子以增强:
单序列增强(ssa):
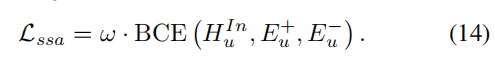
ω : the pre-computed weights to reweight the objective function
跨序列增强(csa):
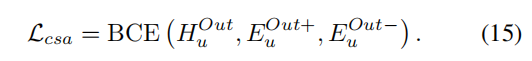
两阶段训练策略:
第一阶段:
使用标准的序列推荐模型,首要目标是学习项的高质量表达,仅使用(13)式;
第二阶段:
应用两个增强模块,最终的目标损失为:
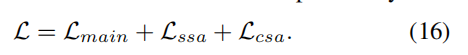
这里不为Lssa和Lcsa设置额外权重:
(1)Lssa在前面已经进行过加权;
(2)在两个增强模块中,数据增强的样本与原始样本在训练过程中被平等对待,每个增强的样本可以被视为在表示空间中生成的一个新的用户和交互。
在推理阶段,所有增强模型都会被停用
During the inference phase, all augmentation modules are deactivated.