03_Attention Mechanisms in Computer Vision:A Survey
来源:https://arxiv.org/abs/2111.07624
1. Introduction
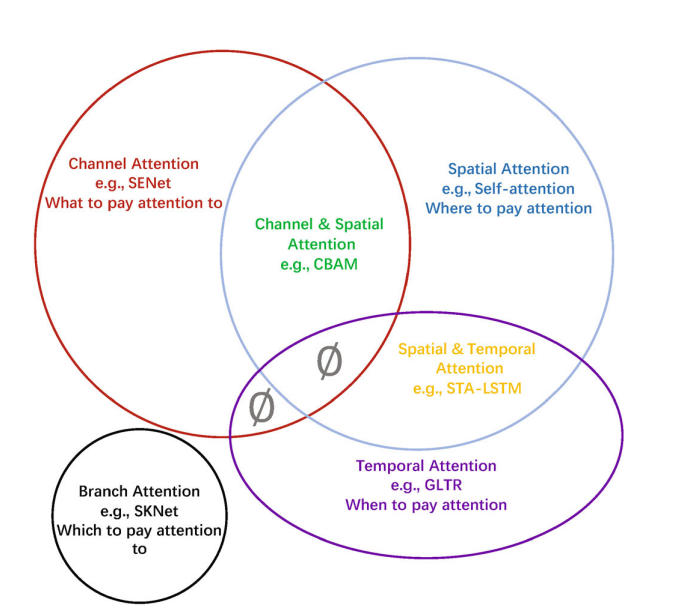
本文为视觉注意力方法的综述,根据数据域将注意力方法分类分组:
- 通道注意力(channel attention): what to pay attention to;
- 空间注意力(spatial attention): where to pay attention;
- 时序注意力(temporal attention): when to pay attention;
- 分支注意力(branch attention): which to pay attention to;
- channel & spatial attention
- spatial and temporal attention
图片展示如下:
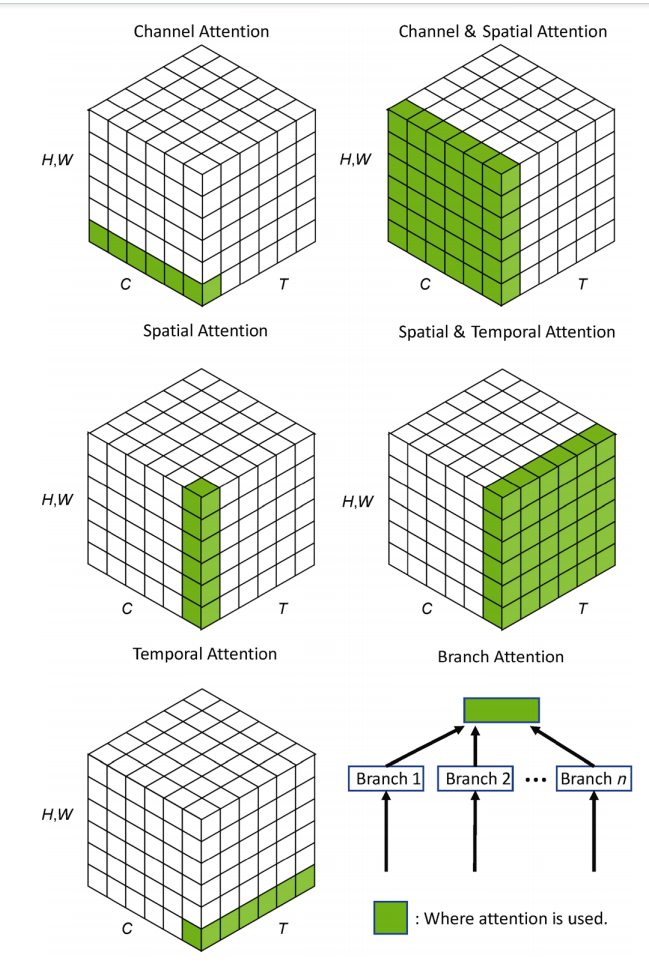
2. Other surveys
3. Attention methods in computer vision
3.1 通用形式
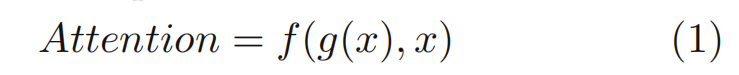
- g(x): 生成注意力权重,对应人类视觉中关注重要区域的过程;
- f(g(x),x): 根据注意力权重处理输入x, 类似于处理关键区域并提取信息
示例:
自注意力(self-attention):
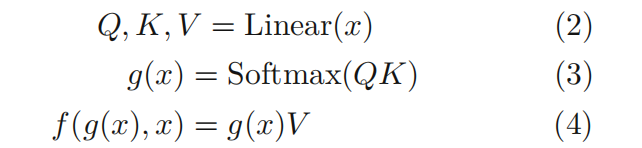
说明:
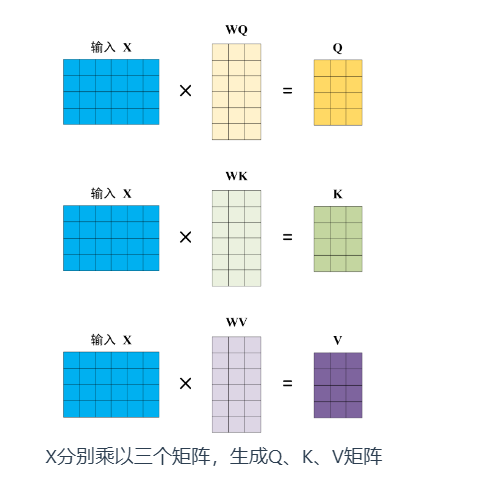
- 其中,WQ,WK, WV 是三个可训练的参数矩阵,不直接用X,而是使用经过矩阵乘法生成的Q, K, V, 增强模型的拟合能力
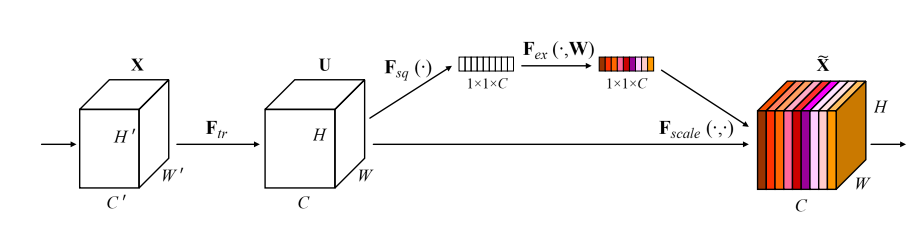
SE注意力(squeeze-and-excitation attention):
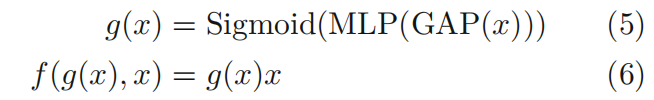
3.2 channel attention
在深度神经网络中,不同通道通常代表不同特征;
通道注意力的作用是自适应地调整每个通道的重要性;
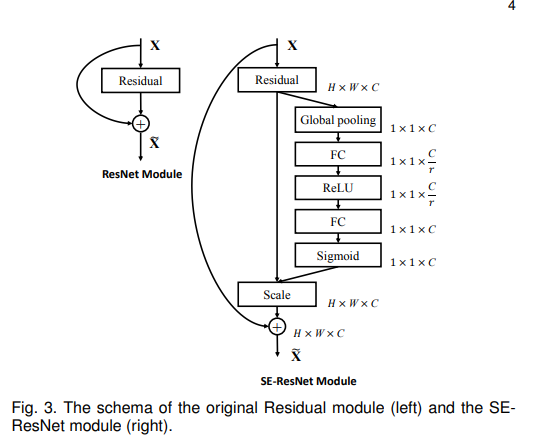
3.2.1 SENet
核心是一个SE块,用于收集全局信息,捕获通道关系,并提高表示能力
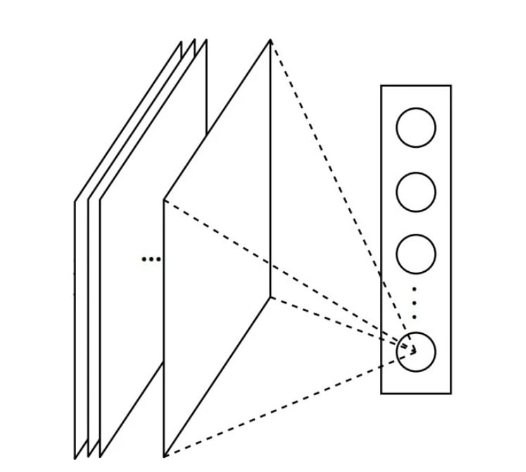
注:Global pooling, 以Global Average Pooling(GAP)为例,参考:https://0809zheng.github.io/2021/07/02/pool.html
- 使用GAP将整个特征图中每个通道的所有元素取平均进行输出;
- 相当于为每一个分类类别指定一个通道的特征图,使用该特征图的平均值作为该类别的概率
- 使得卷积神经网络对输入尺寸不再有限制,且没有引入额外的参数,因此没有增加过拟合的风险
- SE模块先经过一个全局池化层,shape变成
1*1*C, 成为一个全连接层的输入; - 压缩Squeeze: 放入第一个全连接层,输出变为C/r,r是事先设置的参数;
- 激活Excitation: 再接上一个全连接层,输出是C个元素;
- 得到的C个元素,刚好表示原来输出特征图中C个通道的一个权重值;让C个通道上的像素值分别乘上得到的C个元素,该步骤为上图的Scale, 乘法在第二张图中彩色部分体现较直观
回到本论文:
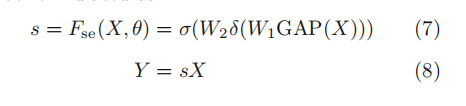
SE块主要功能:
- 增强重要通道,抑制噪声;
- 计算资源需求低,可以在每个单元后面添加。
缺点(后续工作在进行改善):
- Squeeze中,GAP太简单,不能充分捕捉全局信息;
- Excitation,全连接层增加模型的复杂度
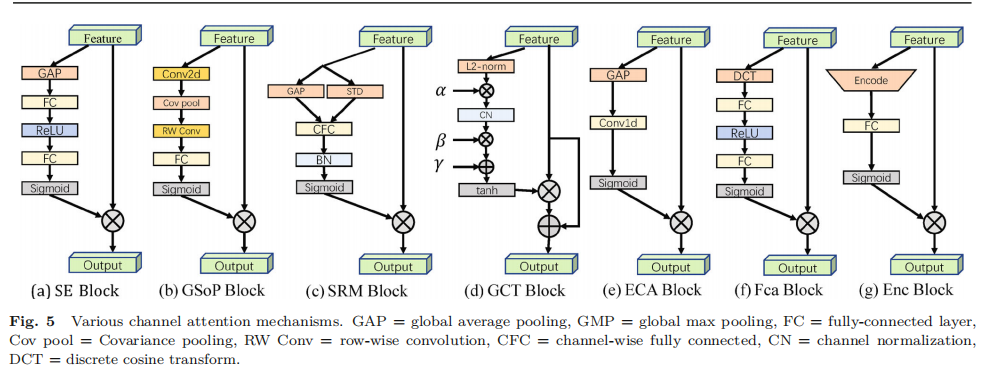
3.2.2 GSoP-Net
改进SE的squeeze模块,通过使用GSoP(global second-order pooling)代替SE中的GAP
squeeze module:
使用1 * 1卷积,使通道数由c到c’
- 对于每个通道计算协方差矩阵(计算方法:https://blog.csdn.net/shyjhyp11/article/details/13445425
- 对协方差矩阵进行row-wise normalization,结果矩阵matrix(i,j)表示第i通道和第j通道的相关性;
excitation module:
- 使用行卷积(row-wise convolution), 输出一个向量;
- 再使用全连接层,和sigmoid函数,得到一个c维的注意力权重;
- 将注意力权重与输入相乘;
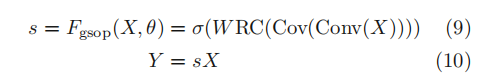
提高了SE块的收集全局信息的能力;
以额外的计算为代价,因此通常被添加在几个残差块之后。
3.2.3 SRM(style-based recalibration module)
将风格转移和注意力机制结合起来。
对于输入特征图X,首先通过风格池化收集全局信息
注:风格池化(style pooling)
对于每个通道,计算均值、方差,拼接成风格向量:
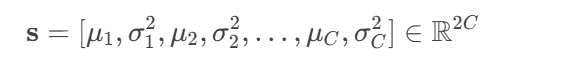
- 使用CFC(channel-wise fully connected),BN,sigmoid,得到注意力权重矩阵;
- 与输入特征相乘
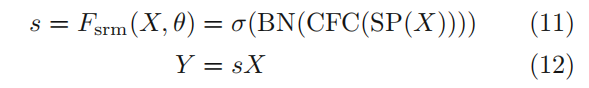
3.2.4 GCT(gated channel transformation)
SE的excitation部分使用全连接层,计算复杂度较高,参数较多,不适合在每个卷积层后面使用;
同时使用全连接层建模通道关系是隐式的过程,提出GCT以在明确地建模通道关系的同时有效收集信息。
- 计算每个通道的L2范数;
- 通过一个可学习的向量α对范数进行缩放;
- 使用CN(channel Normalization)的竞争机制进行通道间的交互;
- 采用可学习的尺度参数γ和偏移参数β对归一化进行重缩放;
- 使用tanh而不是sigmoid, 避免梯度消失问题,得到注意力向量s;
- 最终的注意力向量不仅与输入相乘,而且增加了一个身份连接
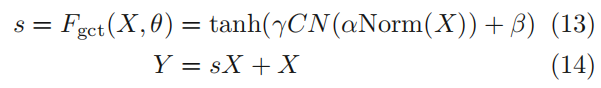
跟SE相比有更少的参数,可以在CNN的每个卷积层后添加。
3.2.5 ECANet
为了避免较高的模型复杂性,SENet减少了通道数量,降低了结果质量,因此提出ECA(efficient channel attention), 使用1维卷积而非降维。
ECA块只考虑每个通道与其k个最近邻之间的直接交互以控制模型的复杂性。
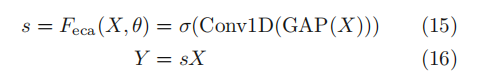
其中,k根据通道数C自适应计算(产生过程如下),1维卷积有k个通道
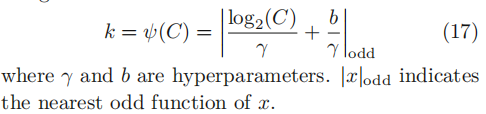
3.2.6 FcaNet
只在squeeze模块使用GAP限制表达能力,经过重新分析了频域(?)的GAP,证明了GAP是离散全局变换(DCT)的一种特殊情况,由此提出一种新的多光谱信道注意方法(multi-spectral channel attention)
- 将X拆分至通道数为C’;
- 对每个子块进行2D DCT,2D DCT可以使用预处理结果减少计算量;
- 所有结果拼接成一个特征向量;
- 全连接层,ReLU, sigmoid同SE,得到s注意力向量;s同输入相乘,同SE
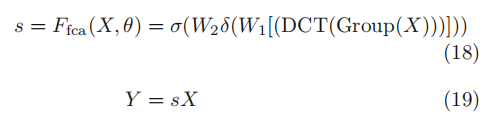
该工作基于信息压缩和离散余弦变换,在分类任务取得良好性能
3.2.7 EncNet
受SENet的启发,提出EncNet, 通过上下文编码模块 (CEM) 结合语义编码损失 (semantic encoding loss,SE-loss), 以建模场景上下文与对象类别概率之间的关系,从而利用全局场景上下文信息进行语义分割。
学习K个聚类中心D={d1,d2,…dk}, 以及一组平滑因子S = {s1,…sk}
使用soft-assignment(高斯权重),计算输入特征到聚类中心的距离,并求和,获得描述符;
对所有聚类中心的特征描述进行聚合而不是连接:
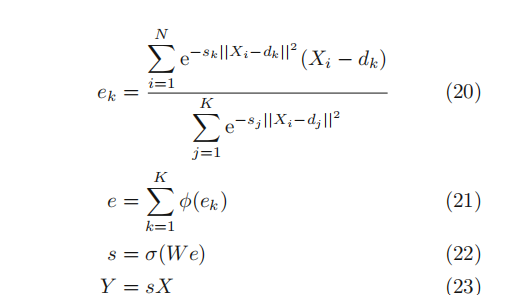
dk 和 sk是可学习的参数,φ表示BN + ReLU;
应用了紧凑的上下文描述符e以计算SE-loss来正则化训练,提高了对小对象的分割;
增强了类依赖的特征图;迫使网络平等考虑大小对象;
由于其轻量级,CEM可以应用于各种主干,只有较低计算开销
3.2.8 Bilinear attention
提出之前的注意力机制只适用一阶统计信息(均值、方差等),而忽略了高阶。因此提出bilinear attention block(bi-attention), 在保留空间信息的同时,捕捉通道之间的高阶特征交互。
使用AiA(Attention-in-Attention),
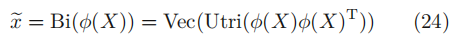
ϕ表示一个用于降维的嵌入函数
将内通道注意机制应用于输入图:
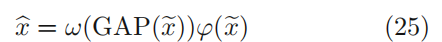
ω 和ϕ 是嵌入函数

与其他模型相比,该模型更关注高阶统计信息