04_GLINT-RU:Gated Lightweight Intelligent Recurrent Units for Sequential Recommender Systems
来源:KDD’25 https://dl.acm.org/doi/10.1145/3690624.3709304
代码:https://github.com/szhang-cityu/GLINT-RU
问题的引出
- Transformer-based models 在 Sequential Recommender Systems(SRSs)中很受欢迎,但计算开销大,推理速度慢;
- 现有efficient SRS难以在潜在表达中填充高质量的语义和位置信息;
提出GLINT-RU, Gated Lightweight IntelligeNT Recurrent Units.
准备工作
1. Gated Recurrent Units(门控循环网络)
- 捕捉item序列之间的依赖关系(例如用户点击/购买的顺序);
- 动态调整记忆单元的内容(即根据新的输入决定保留多少历史信息,丢弃多少旧信息)
GRU的公式机制:
更新门:保留多少旧信息
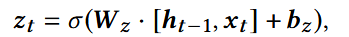
重置门:遗忘多少旧信息
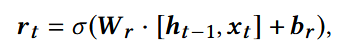
候选隐藏状态:新的候选特征
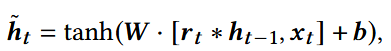
最终隐藏状态:综合旧信息和新信息,得到更新后的状态
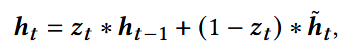
严格顺序更新,序列信息没有显式的全局交互;对远距离的item依赖捕捉能力不足;
导致GRU在复杂推荐场景里,难以充分建模序列中所有item的复杂关系
2. Linear Attention Mechanism(线性注意力机制)
传统点积注意力计算复杂度:O(N2d)
线性注意力机制计算复杂度:O(Nd2)
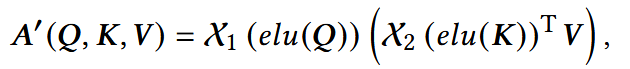
- X1, X2: 行归一化(row-wise L2 normalization), 列归一化(column-wise L2 normalization);
- Q,K,V: 可学习的查询(Query), 键(Key), 值(Value)矩阵;
- A‘:注意力得分。
注:ELU(Exponential Linear Unit, 指数线性单元)

GLINT-RU
1. 总体结构
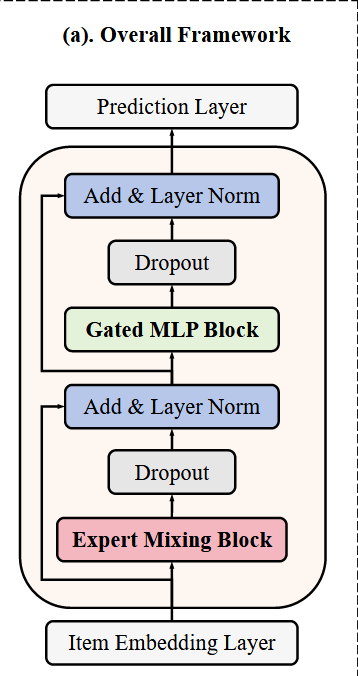
2. Item Embedding Layer
For sequential recommendation tasks, information on items interacted by users should be encoded to tensor through the embedding layer.
- N: 用户-物品交互序列的长度;
- d: embedding size,嵌入向量的维度
对于一个交互序列si = [v1, v2, …, vn, … , vni], 第n个物品vn ∈ RDn,可通过下面公式投影为en:
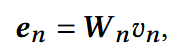
Wn ∈ Rd x Dn, 可训练的权重矩阵
输出: E = [e1, e2, … , eN]T.
传统的基于Transformer模型中,通常需要位置嵌入,因为注意力机制本身无法编码时间信息;本文中采用GRU模块来建模项目的时间依赖关系,因此不添加位置嵌入层。
3. Dense Selective GRU
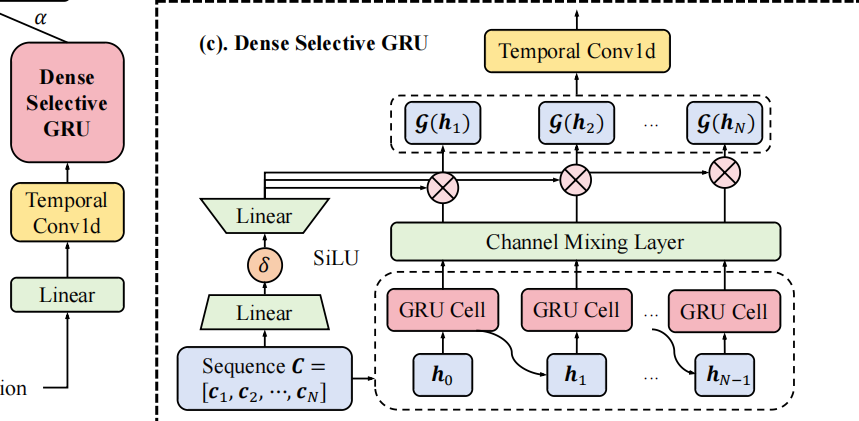
3.1 Dense GRU module
输入前,做Temporal Conv1d:
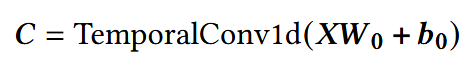
- X:经Item Embedding Layer获得的tensor, 形状N x d, 每一行是一个item的嵌入向量;
- 卷积核大小:k,在计算第n个输出时,考虑的是输入序列中相邻k个item的特征;
- C:仍然是长度为N的序列(使用padding),每个元素Cn是经过卷积后,第n个时间步的局部特征表示。
GRU更新机制:
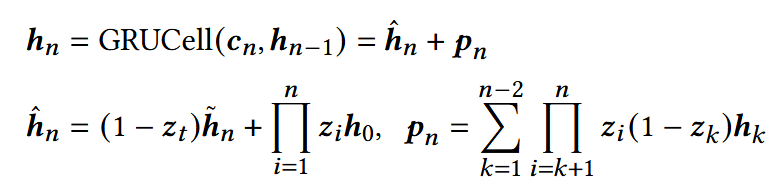
- 隐藏状态hn被拆分为两部分:hat hn: 潜在的item表示,pn: 细粒度的位置信息;
- Dense GRU: 将hn拆分,显示建模内容 + 位置依赖;避免了额外的位置嵌入层;
Channel Crossing Layer(通道交叉层):
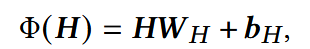
- H:GRU的输出
输出后,再做Temporal Conv1d:
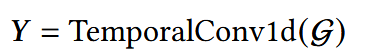
- G:选择性门控函数;
- Y:dense selective GRU模块生成的输出矩阵;
- 通过两个卷积层与GRU单元相结合,使得每个隐藏状态不仅依赖于紧邻的输入时间步,还能够从更多历史行为中学习表示。
3.2 Selective Gate
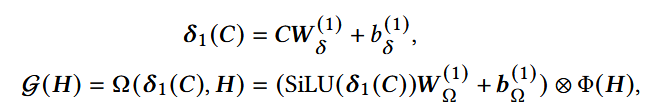
- C: 输入序列,也即GRU的输入;
- H:GRU隐状态输出序列;
- ⊗:逐元素相乘;
- Φ(H): 对H做线性或非线性变换;
- SiLU(x) = x · σ(x).
4. Expert Mixing Block
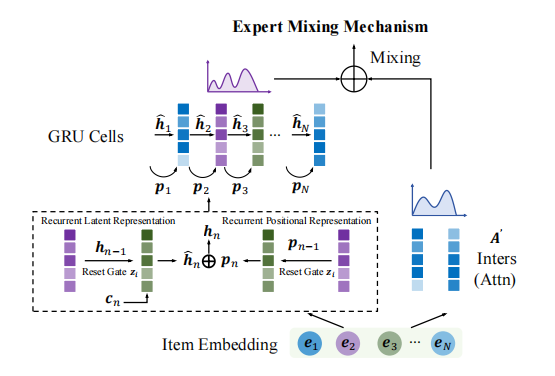
the two employed experts are parallel in the framework(Linear Attention & Dense Selective GRU)
通过mixing gate给两个experts分配权重:
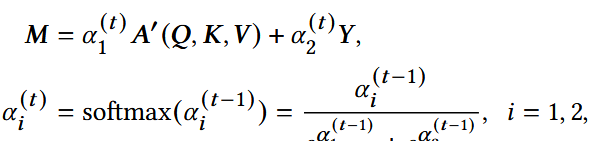
- α1(t) , α2(t) :第t次训练迭代的可训练混合参数;
使用数据感知门过滤输出(data-aware gate):
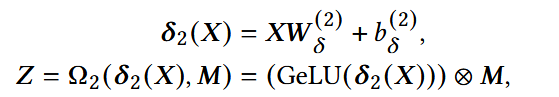
- X: expert mixing block的输入
5. Gated MLP(Multilayer Perceptron, 多层感知机) Block
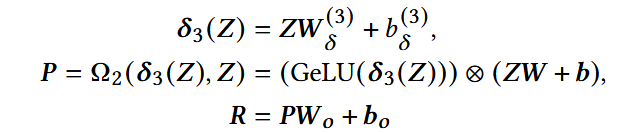
- Z: expert mixing block的输出;
- P:gated linear layer的输出;
- R:item representation;
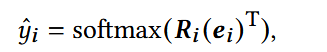
- 物品表示R与物品嵌入ei做内积,得到原始得分;
- softmax对所有候选物品进行归一化,得到每个物品的预测概率;
- hat yi :第i个物品的推荐分数。
复杂度分析
序列长度为N,嵌入维度d,卷积核大小k,整体时间复杂度为O((2k+12)Nd2)
实验
leave-one-out策略,倒数第二个交互序列用于验证
Recall

Mean Reciprocal Rank(MRR, 平均倒数排名)

Normalized Discounted Cumulative Gain(NDCG)

均为越大越好
移除Gated MLP: 称为Light GLINT-RU, 适合资源受限场景
参数影响:
- Kernel size k:
- 增大k可以聚合更多item信息,学习更广泛的上下文,从而提升性能;
- 过大,可能引入无关信息,导致准确率略微下降;
- 所有kernel size下均稳定高效,增大对推理时间和GPU内存占用影响较小。
- Hidden size d:
- 小hidden size下,也能达到其他基线的性能上限;