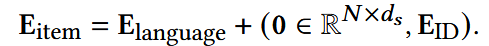05_AlphaFuse:Learn ID Embeddings for Sequential Recommendation in Null Space of Language Embedding
来源:SIGIR‘25 https://arxiv.org/abs/2504.19218
代码:https://github.com/Hugo-Chinn/AlphaFuse
问题的引出
- 早期工作,给每个item分配一个独有的ID,学习ID embeddings => capture collaborative signals within the interaction behavior space
- 可训练的,强调用户之间的协作信号
- 近期工作,利用LLM,将item文本的元数据(标题,描述等)编码为 language embedding
- 冻结的,捕捉item的语义和上下文信息
- 引出问题:
- language embeddings 如何有效的指导ID embedding的学习?
- language embeddings 如何更好的整合进入item embedding?
对于问题1已经存在一些方法, 存在局限:
语义空间的退化: 语言嵌入需要高维表示,而ID嵌入的表示是低维的;
Degeneration of semantic space
没有充分利用语言嵌入: 只作为引导,而没有将其放入最终的item embeddings;
Underutilization of language embedding
辅助可训练参数的参与
Involvement of auxiliary trainable parameters
ID embeddings should be semantic-anchored(i.e., preserving the original semantic space of language embeddings) and tuning-efficient.
AlphaFuse:
- Decomposition of semantic space: 分为semantic-sparse(null space)和semantic-rich(row space);
- Clipping of null space:丢弃一些维度,通常为64或128维;
- Standardization of semantic-rich subspaces;
- Learning of ID embeddings.
准备工作
1. 符号表示
V:所有的物品集合
U:所有的用户集合
N, M:物品数量,用户数量
L:历史交互序列长度
v<=L = [v1, v2, … ,vL-1, VL]: 用户过去的交互历史
2. 判别式序列推荐(discriminative sequential recommenders)
目标:依据用户历史交互 v<L , 获得vL (在所有物品里找到用户真正会选的那个,即分类问题)
做负采样,N为负样本数,以 v<L 预测 vL
直接在全量物品上计算代价太高,使用负采样集合来近似训练
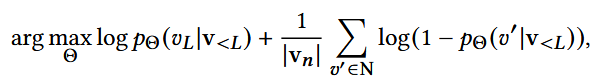
- Θ:一系列可训练的模型参数
- 第一部分:最大化正样本概率;第二部分:最小化负样本概率
推理过程:
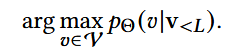
3. 生成式序列推荐(generative sequential recommenders)
每个物品 v ∈ V,被映射为一个embedding 向量 e ∈ Rd
历史交互可以表示为:e<L = [e1, e2, … , eL-1], 正样本也就是eL
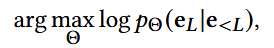
最大似然估计:已知eL已经发生,求得使该事件发生概率最大的Θ(可训练参数)
推理过程:
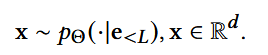
x并不保证恰好是某个物品的embedding, 需要映射步骤:最近/学习一个映射函数
4. 基本子空间
embedding矩阵为:E ∈ R N × d
做奇异值分解,SVD(ETE) = UΣUT
- U ∈ Rd×d : 包含所有特征向量;
- Σ:对角矩阵,σ2:奇异值的平方,按降序排序
把embedding空间 Rd 拆分成一组正交子空间,每个子空间对应一个奇异值
SVD见:https://blog.csdn.net/lomodays207/article/details/88687126
三个基本子空间:
Singular Subspace: 所有和某个奇异值 λ 对应的奇异向量张成的空间
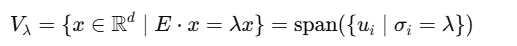
如果一个σ很大,说明embedding在其对应的u方向信息最强
Row Space: 等价于E的所有行向量张成的空间
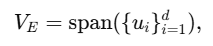
embedding 矩阵实际能表示的所有方向
Null Space: 对应奇异值为0的空间
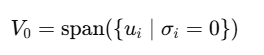
E在这些方向上完全没有分量,因此E与零空间是正交的
可以认为是语义稀疏或丢失的维度

AlphaFuse
a new language-guided learning strategy for ID embeddings
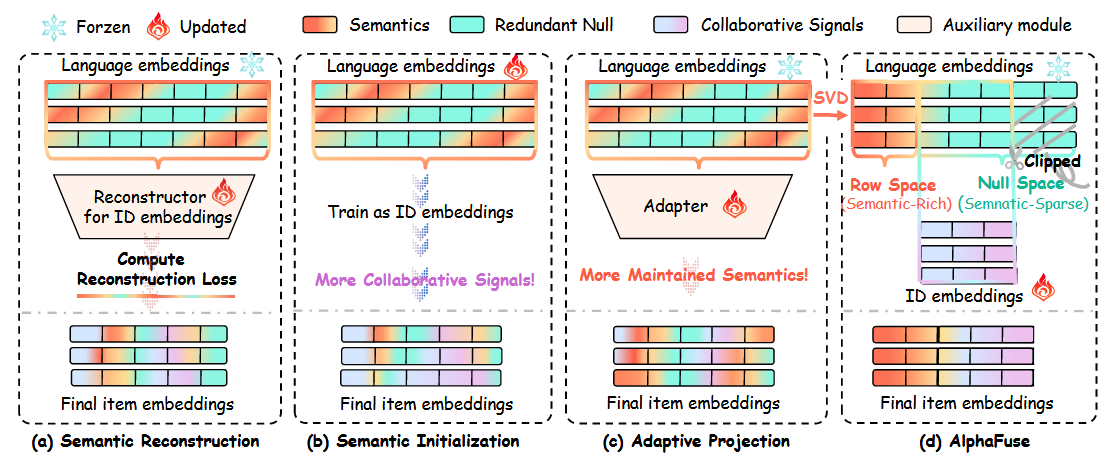
1. Modeling Language Embeddings
将 item 的文本属性和描述拼接起来;
- 输入开源LLM如Llama或公开API,获得language embeddings;
- 获得language embedding:E ∈ RN×dl, embedding维度也就是dl
2. 分解语义空间
对于E: 通过SVD做 rank-r 近似,得到E*r , 使得下式最小化:
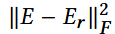
即在低维空间尽量保留原embedding语义信息。
Frobenius范数:矩阵元素平方求和,再开方; 在所有秩<=r的矩阵里,找一个和E更接近的
(1) 在做SVD前,计算 E 的均值和协方差(方阵):
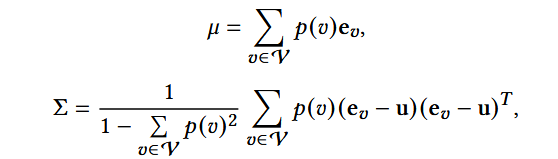
- p(v): item v的权重,默认平均
(2) 对协方差矩阵做SVD:
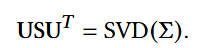
SVD见:https://blog.csdn.net/lomodays207/article/details/88687126
- S:特征值矩阵,奇异值的平方
- 右奇异矩阵可用于特征维度的压缩
(3) 划分奇异子空间
每个奇异向量对应一个一维奇异子空间:
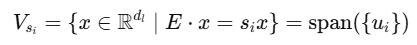
每个ui是语义空间中的一个主方向,该方向的重要程度由其对应的奇异值si决定
奇异值更大的奇异子空间包含更多E的投影,因此保留了更多信息;
零奇异值对应的null space与E正交 (积为0),不包含任何语义信息。
3. 处理奇异子空间
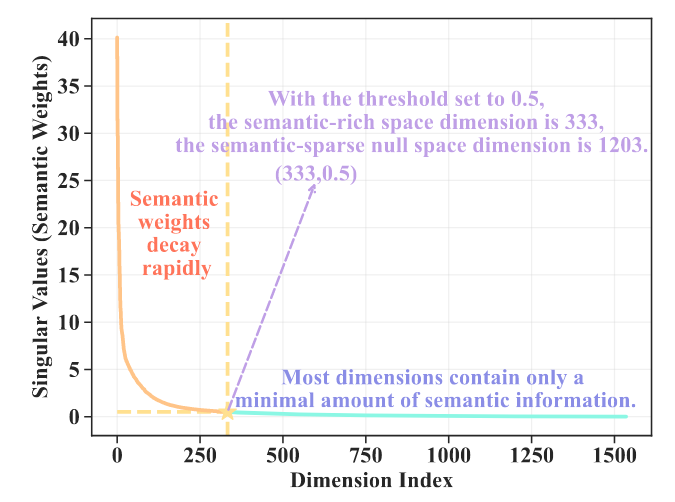
由于SVD数值误差,小的奇异值不会是0,只会是很小的正数。因此人为设定一个阈值,小于阈值的奇异值就当作无语义,即null space。
- 语义空间的低秩结构(Low-rank structure): 语义信息主要集中在很少数的几个大奇异值的子空间中;
- 语义空间的各向异性(Anisotropy):即使在semantic-rich子空间中,不同维度的重要性差别也很大。
(1) Clipping of Semantic-sparse Null Space
传统的判别式序列推荐模型:
ID embeddings一般是低维的(64或128),如果把几千维的null space输入,可能导致:
- 噪声维度过多,学习困难;
- 模型参数增大,训练和推理都低效
因此要将null space裁剪,裁剪后的null space记作V0, 维度dn
扩散模型类的生成式推荐模型,适合高维空间,无需对null space裁剪
(2) Standardization of semantic-rich Subspaces
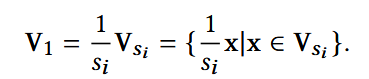
即每个子空间的基向量V除以它对应的奇异值s。
减轻semantic-rich子空间之间语义信息的差异性,确保language embedding更有效,更易于区分。
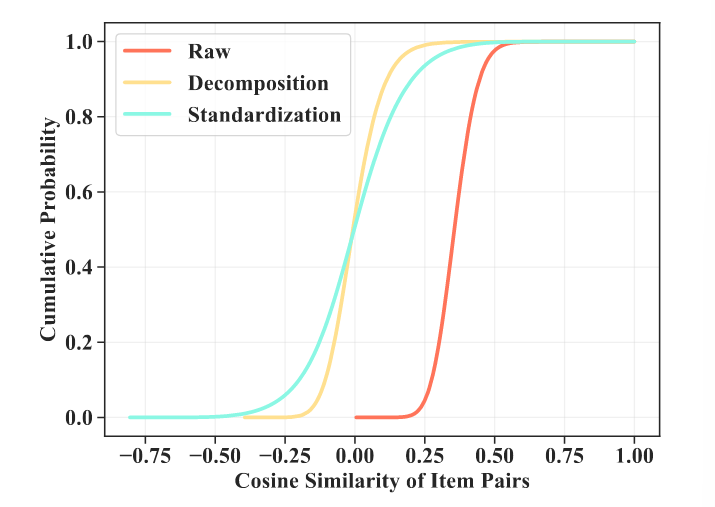
4. Learning of ID embeddings
semantic-rich子空间V1, 维度为ds
(1) language embeddings in the standardized semantic-rich subspaces V1 计算如下:
这里由于SVD后,semantic-rich空间已经包含了绝大多数语义信息,所以可以近似看作language embeddings
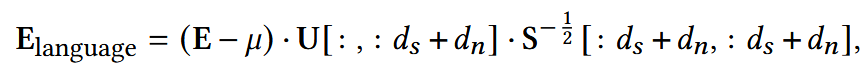
- μ:E的均值
先进行中心化,再投影到前ds+dn个奇异向量(保存前ds个重要特征),最后对每个方向除以相应奇异值(S存放奇异值的平方,S的二分之一次幂即为奇异值,-1即由乘变除)
提前预留dn,用于放置可训练的ID embeddings.
为什么null space也要标准化?
- null space也会存在少量语义信息;
- 部分扩散模型要求方差守恒,否则扩散生成过程会失效。
(2) ID embeddings初始化为零或随机
(3) 拼接为最终的item embedding: