06_Multi-Modal Multi-Behavior Sequential Recommendation with Conditional Diffusion-Based Feature Denoising
来源:SIGIR‘25 https://arxiv.org/abs/2508.05352
问题的引出
用户在不同的行为下,对不同的模态展示出不同的偏好;
用户可能更容易被图片吸引而点击;同时可能会更在意文本形容而收藏
难以有效的减轻用户行为中的隐形噪音;
意外的点击行为等
难以控制多模态表示中的噪声
例如,广告行为,一个商品的图片上展示“低价”字样,即使用户是被商品吸引的,推荐系统也可能误认为用户是被“低价”吸引,而推荐用户不感兴趣的其他廉价商品
Multi-Modal Multi-Behavior Sequential Recommendation(M3BSR):
使用一个 conditional diffusion model 去除多模态表示中的噪声;
使用深层的行为信息去指引扩散模型对浅层行为信息进行去噪;
例如,使用favorite行为指引click
使用 Multi-Expert Interest Extraction 层
准备工作
1. 符号表示
行为集合:B = {cl, fa}, cl: 点击行为, fa: 喜欢行为
模态集合: M = { id, im, te}, id: 物品身份, im: image, te: text
对于每个用户u,有如下两个行为序列:
Su,cl = ( su,cl,1, su,cl,2, …)
Su,fa = ( su,fa,1, su,fa,2, …)
加上不同模态则可表示为:Sidu,cl
2. 扩散模型
forward diffusion process: 一步步往数据里加噪音,每次加多少只取决于上一次的样子
马尔可夫链,即未来的状态只依赖于当前的状态,而与过去的状态无关。
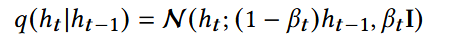
N :正态分布
β :控制每一步加多少噪声
将上一步集中在ht-1的高斯分布进行略微拉伸,峰值变低,范围变大,使其分布在ht-1附近,而非仅在一点
采样形式:
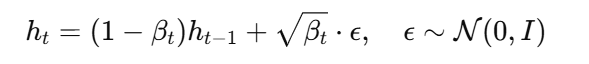
reverse denoising process: 训练一个去噪模型,让其学会恢复真实的特征
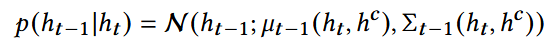
- u,Σ: 训练得到
采样形式:
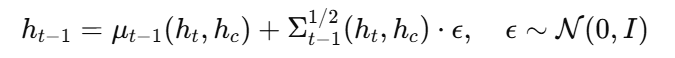
M3BSR
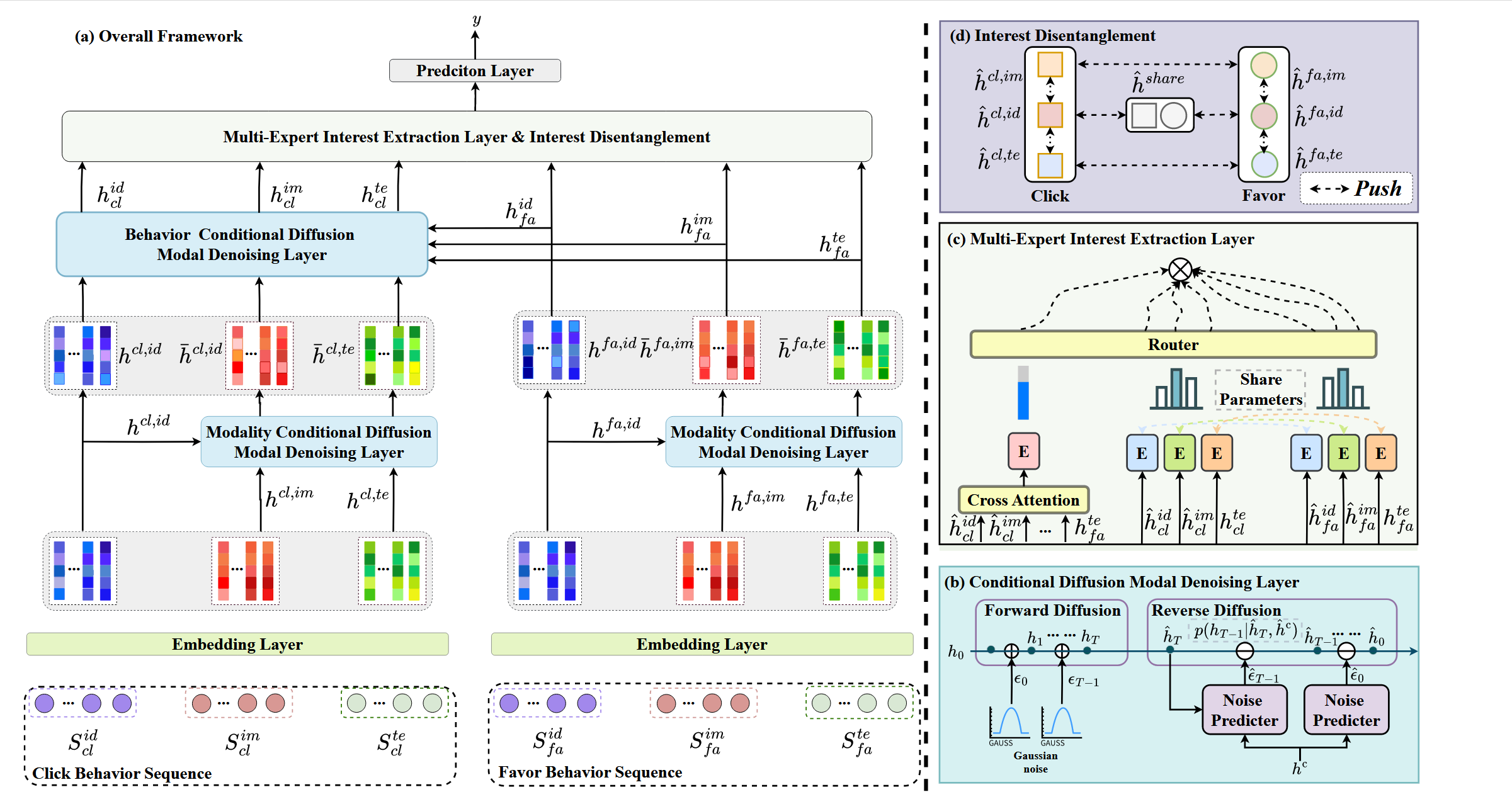
1. 多模态多行为输入层
id:
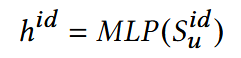
- 在embedding表中进行查表,如id = 0对应表中第一行。该表为随机初始化,后续随模型进行训练更新;
- 将表中相应向量通过MLP层,得到ID模态的嵌入表示
img & text:
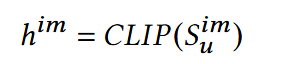
CLIP(Contrastive Language-Image Pre-training)
学习一个共享的语义空间,让图片和文本能够对齐;在这个空间中,“描述一张图片的文本”和“图片本身”的向 量要尽可能接近,而不相关的要分开。这里使用CLIP提取出来的对于一个item, him,和hte余弦相似度会比较高。
2. Conditional Diffusion Model Denoising Layer
(1) Denoising for Different Modalities: 以ID为条件指导图像与文本进行去噪
前向扩散:
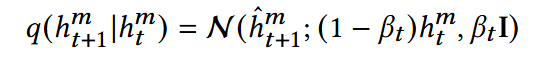
- h_hat : 含噪声的图片和文本特征向量
标准写法:均值处应为根号(1 - β),但当β很小时,二者可以认为相等;
h或许可以全加hat
已知当前加噪,想要获得下一步加噪,分布为:均值(1 - β)h,方差βI的正态分布
可理解为:原本全部分布在h,加噪后,使得正态分布略微更均匀,峰值降低,扁了一些
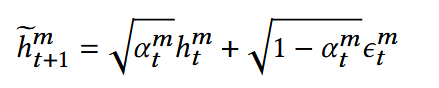
由μ + σε而得,得到加噪后h的具体表示
- ε:噪声向量
- α:加入噪声的强度
反向扩散:
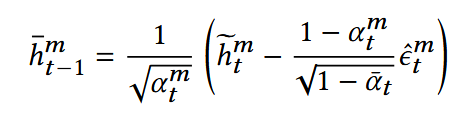
为什么不将原来的ε保存起来,而是训练一个神经网络来估计它?
如果想要解出ε,由前向扩散公式逆推应为:
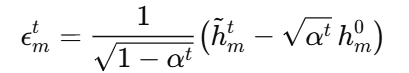
可以看出,必须已知干净的h。但在反向扩散时,模型只能见到已经加噪后的h,因此无法通过这种方法计算出来。
ε计算:
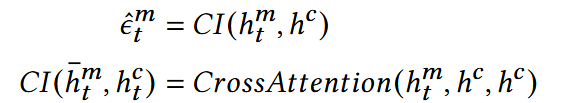
- hc = hid
通过CrossAttention, 得到him(干净+噪声)与hc(干净)的差异,因此可以视为噪声
Optimization(MSE & KL散度):
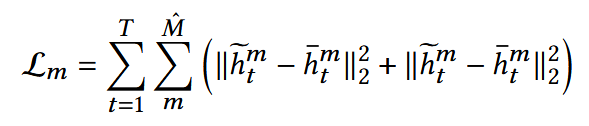
让反向扩散模型预测的分布尽量逼近前向扩散的真实分布
(2) Denoising for Different Behaviors: 以喜爱行为为条件指导点击行为进行去噪
前向扩散:
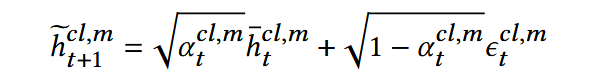
反向扩散:
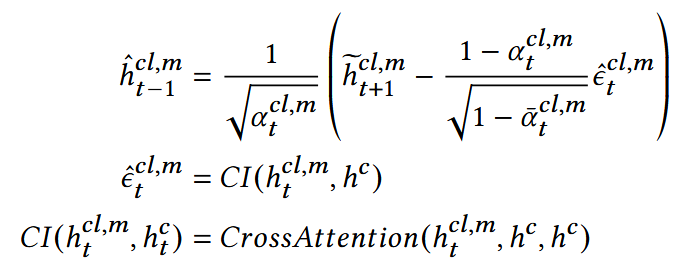
Optimization:
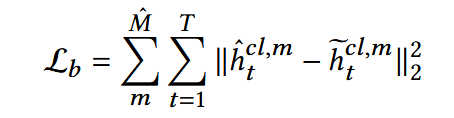
- h_hat: 减噪后的点击行为特征向量
3. Multi-Expert Interest Extraction Layer
(1) Common Feature Extraction
对于有某种爱好的人来说,无论是以哪种模态呈现,用户都会保持该偏好,该层设计以捕捉这种普遍特征。
将各个由反向扩散去噪的模态进行拼接:
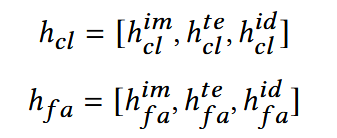
两种行为做CrossAttention:
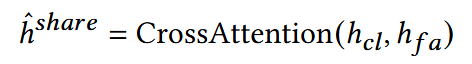
使用Transformer捕捉更深层的特征:
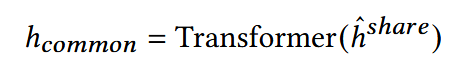
(2) Unique Feature Extraction for Click and Favor Behavior
用户在点击行为和喜爱行为可能展现出对不同模态的不同偏好。
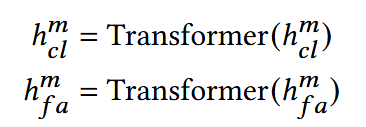
(3) Interest Disentanglement
对于上面获得的:
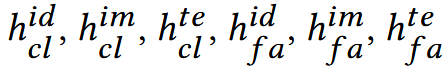
分开以捕捉独特的语义信息。
对比损失函数:拉近正样本对(同一个物品的多模态表示,同一个用户不同行为序列中的相同物品表示),退远负样本对(不同item的表示)
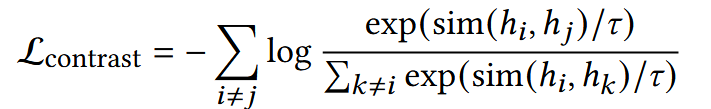
- τ:超参数,控制对比学习中,相似度的敏感性
确保同一个物品在三个模态的embedding一致,减少模态误差
(4) Interest Routing Fusion
学习一个gate权重g,动态调节公共兴趣与行为兴趣的比例
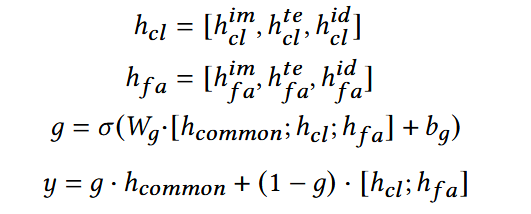
- 当g较大时,更多的依赖公共兴趣;
当g较小时,更多的依赖行为兴趣;
- W,b: 可学习参数;y:最终融合特征。
预测与优化目标
1. 使用全连接层预测用户下一步会选择的物品
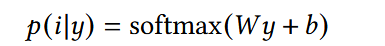
已知用户兴趣y的情况下,认为其选择i的概率
2. 交叉熵损失衡量预测分布和真实交互物品之间的差距
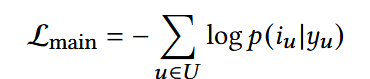
3. 整体优化目标

- λ:超参数