07_Unleashing the Potential of Diffusion Models Towards Diversified Sequential Recommendations
来源:SIGIR’25 https://dl.acm.org/doi/10.1145/3726302.3730109
问题的引出
现有方法中,用户的偏好表示是确定性的
常规流程为:每个物品ID对应一个固定的embedding,再经过Transformer, 得到一个表示用户整体兴趣的向量。但由于输入的embedding是固定的,输出的兴趣向量也是固定的,没有不确定性。
现有方法只生成一个item embedding
扩散模型会尽量生成一个和用户最主要偏好一致的商品,推荐时,挑出一堆和这个生成embedding最相似的物品。
用户看了:3部动漫,1部动作,1部恐怖;动漫占比最大,扩散模型推理时,生成了一个动漫电影的embedding,最终找到很多和这个embedding接近的动漫电影。
diversity-guided diffusion model for SRSs (DiffDiv)
- A new diversity-aware guidance learning module (DAGL)
- A new accuracy-diversity balanced optimization strategy (ADBO)
- a new heterogeneous diffusion inference (HDI)
准备工作
1. 多样化推荐(Diversified Recommendations)
多样性可分为两类:
- 个体多样性(individual diversity): 关注单个用户的推荐列表要不要多样化;
- 整体多样性(aggregate diversity):关注所有用户的推荐列表整体是否覆盖广泛的物品空间。
多样化推荐方法主要有两类:
- 多阶段方法(multi-stage): 推荐列表是迭代生成的
- maximal marginal relevance(MMR, 最大边际相关性),逐个推荐商品,要求新推荐的商品不能与之前的太相似, 贪心算法
- 单阶段方法(one-stage): 推荐列表是一次性生成的
- learning-to-rank:在训练时引入多样性目标,让模型学会直接输出多样化的推荐列表;
- clustering-based:相似物品将会被分到同一簇,从不同簇中各选一些物品,从而保证多样性。
本文为individual diversity & one-stage
2. Diffusion Models for SRSs
在序列推荐中,基于扩散模型的方法主要分为两类:
- 目标物品生成类: 直接生成用户下一步可能交互的目标物品;
- 序列数据增强类:生成额外的物品来增强用户的历史序列,缓解序列稀疏问题
3. 符号表示
序列集合:S = { s1, … ,s|S|}
- 每个序列:s = {i1 , … , in}(s∈S),包含n个item,按时间顺序
item总数:M
- 序列长于n将被截短,短于n的会被填充;
- 任务为:利用前n-1个items {i1 , … , in-1}, 以及他们的embeddings {e1 , … , en-1}, 训练一个模型,去预测 in
The DiffDiv Model
1. Diversity-guided Diffusion Training
Diversity-aware guidance learning
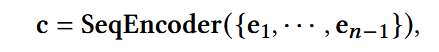
e ∈ Rd : 序列中某一item的embedding
c ∈ Rd: 能够表示用户整体兴趣的上下文embedding
本文中,SeqEncoder选择Transformer
DAGL: 建模数据在一个分布空间能够提高学习数据多样性的能力
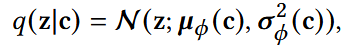
encoder网络: 输出μ和σ;
ϕ:参数集合,映射d -> d‘
将确定的c转换成高斯分布;近似后验:已经看见了c,学习一个正态分布
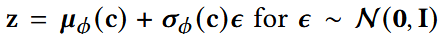
- 重参数化采样z,每次采样到不同的ε,就能得到不同的z
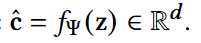
- decoder网络,将潜在的变量z映射回原来的embedding空间,Ψ为参数集合;
- 最终得到的c_hat,即为多样性感知引导。
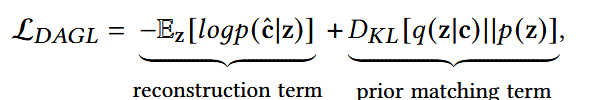
第一项:保证最终结果合理,能够表示用户偏好;

- c与z越接近(-),log值越大,-E[log]越小。
第二项:KL散度,衡量两个分布的差异,其中q为Encoder从c学到的分布,p为一个预设的分布。
Diversity-guided diffusion
x0 <– en
(1) 前向扩散阶段
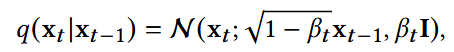
- β:线性增加(linear schedule),从0.0001到0.02
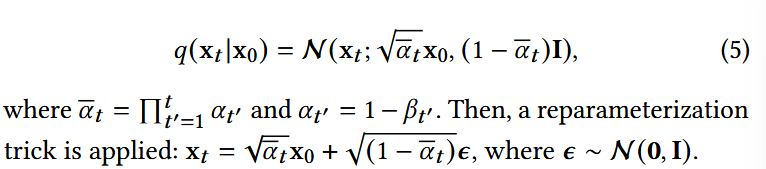
(2) 多样性引导的反向阶段
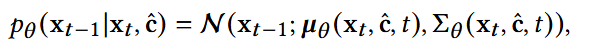
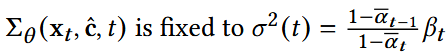
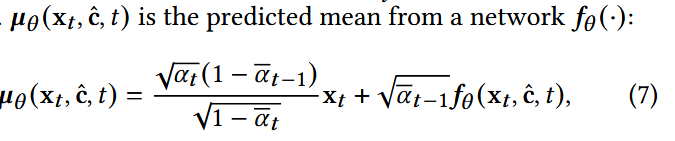
- f: 一个网络带有θ,以预测x0, 这里使用MLP而不是复杂网络
(3) 扩散优化

- 第一项展开同前面,x1与x0越近,E越小;这里保证最近的一步能够直接预测回去;
- 第二项为每个时间步计算一个KL散度。
简化后:
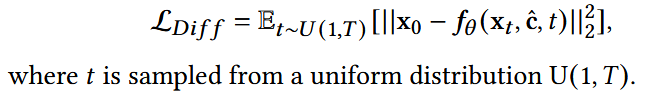
- 每个时间步内采样,使得无论是低噪还是高噪部分,模型输出都能与原始接近。
Accuracy-diversity balanced optimization
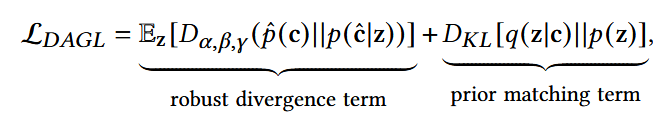
- 使用鲁棒散度(Robust Divergence)替换原来的第一项重构项
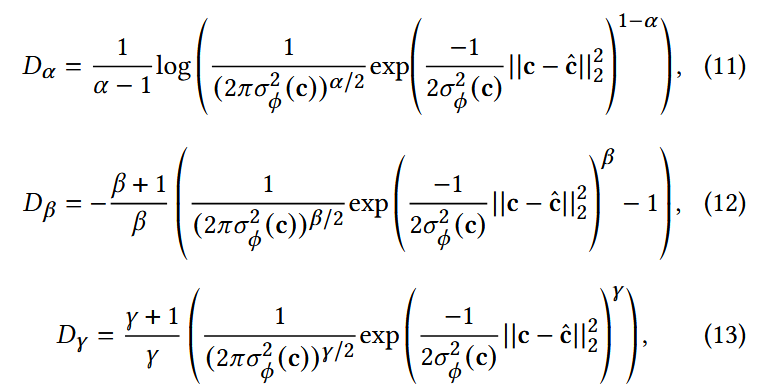
鲁棒散度的原理:对低密度样本的贡献赋予更小的权重
- 概率分布里“离群点”的密度往往比“正常点”低;
- 如果直接用重构损失,离群点也会被强制拟合,带来噪声;
- 用鲁棒散度,可以让模型更加关注“主要分布”,而不是被少量离群点扰动。
最终accuracy-diversity balanced损失:
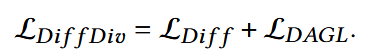
2. Heterogeneous Diffusion Inference Mechanism for Generating Diversified Items
传统基于扩散模型的序列推荐:
- 用用户的主要偏好生成一个item;
- 找到top-k以进行推荐
HDI:使用多个推理通道
- 每个通道l由DAGL采样出的不同引导信号c_hatl驱动,强制每个通道生成的item反映用户对一类商品的偏好;
- 每次采样的ε不同,因此生成的c也不同,则每个通道内的引导可以表现相关但不同的语义空间,因而反映用户不同方面的偏好
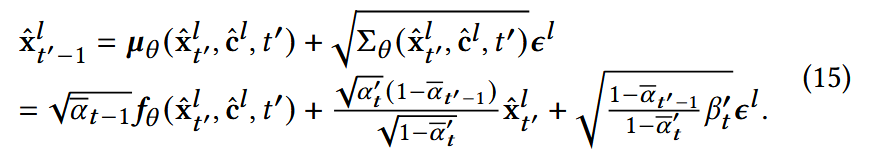
最后可得到:每个表示一种确定的用户偏好,L为推理通道数
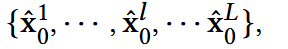
在实际中,用户交互的商品可能与一个他的偏好相关,而不是所有,因此这里取max:
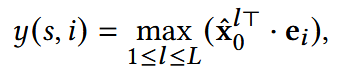
最终选择分数最高的top-K推荐给用户。