08_Mitigating Distribution Shifts in Sequential Recommendation:An Invariance Perspective
来源:SIGIR‘25 https://dl.acm.org/doi/10.1145/3726302.3730036
代码:https://github.com/hermione314/IDEA
问题的引出
- 在真实世界情景,时间变化因素(例如,产品促销,季节变化),会导致用户交互的分布漂移(distribution shifts);
- 当前的方法:
- distributionally robust optimization(DRO): 依赖于“最坏分布”的定义,不同方法的定义都存在缺陷,导致在鲁棒性和准确性之间出现偏差;
- uncertainty modeling:缺少可解释性;
- contrastive learning:依赖于任意设定的数据增强,可能丢弃重要的交互数据同时保留噪音信息,从而误导用户偏好建模;
Invariant Learning for Distribution Shifts in SEquential RecommendAtion (IDEA):
- 环境模拟模块:模拟更多样的环境以模拟真实世界情景;
- 基于不变性的优化模块:捕捉用户不变的偏好。
准备工作
1. Robust Sequential Recommendation
2. Invariant Learning
学习在不同环境下都保持稳定的表示,提升OOD(out-of-distribution) generalization(分布外泛化),避免模型依赖于环境特有的虚假相关。
训练集:牛几乎都在草地上,骆驼几乎都在沙漠里;
测试集:牛出现在沙漠,骆驼出现在草地;
Invariant Learning迫使模型学习动物的本质特征,而不是环境特征。
直接应用于序列推荐存在挑战:
- 用户的行为是时间连续的、上下文依赖的,而不是静态的、独立的样本;
- distribution shifts通常受复杂的潜在因素影响,比如兴趣转移或外部事件
符号表示
(1) 序列推荐
U:users
- V: items
- S = {Su | u∈ U}
- I∈R|v|×d (item embedding matrix)
给定{U,V,S},目的为学习一个模型fθ , 预测用户在T+1时刻最有可能交互的item.
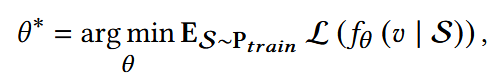
ERM(Empirical Risk Minimization, 经验风险最小化):在训练数据集上,最小化样本的平均损失。
实际上使用BCE:
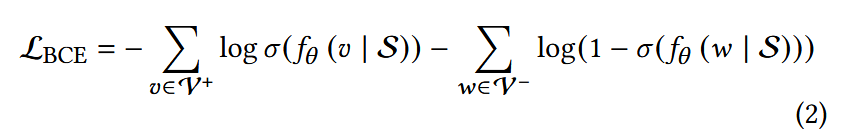
(2) 分布漂移
优化推荐系统模型,使其能够在测试分布Ptest(Ptest ≠ Ptrain)上有好的泛化,即最小化:
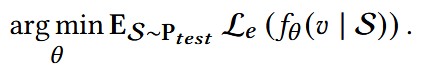
IID (Indpendent and Identically Distributed, 独立同分布): 训练数据和测试数据来自同一个分布,并且各样本之间相互独立,即Ptest = Ptrain, 很多模型会做这种假设。
(3) Invariant Learning
惩罚不同环境下的性能差异,迫使模型只捕捉跨环境都稳定的特征。
训练数据Dtrain被从多个环境ε中采样:Dtrain = {Dm}m∈ε
环境不变性约束(Environment Invariance Constraint, EIC) :
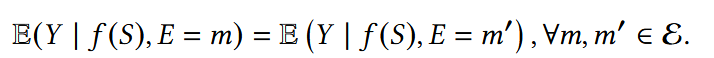
给定表示f(S), 不同环境下标签Y的条件分布应该一致。
IL将EIC作为正则项(penalty term)融入ERM:
IRM-v1:
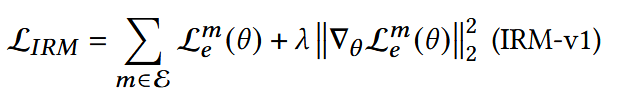
- 第一项:第m个环境里的普通ERM损失;
- 第二项:环境m中,损失函数对参数的梯度。
这里求梯度后平方,是想让所有环境中梯度都能近似于0,也就是要在所有环境中都达到最优;模型只能选择那些在所有环境下都能同时最优的特征。
V-REx: 计算多个环境损失之间的方差(第二项)
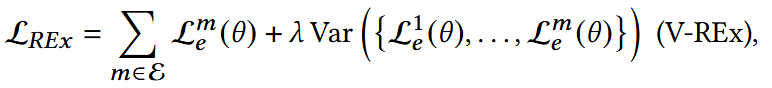
- θ:模型参数
在理想情况,训练数据能够明显的被分割到不同环境;但实际上缺少显式的环境标签
IDEA
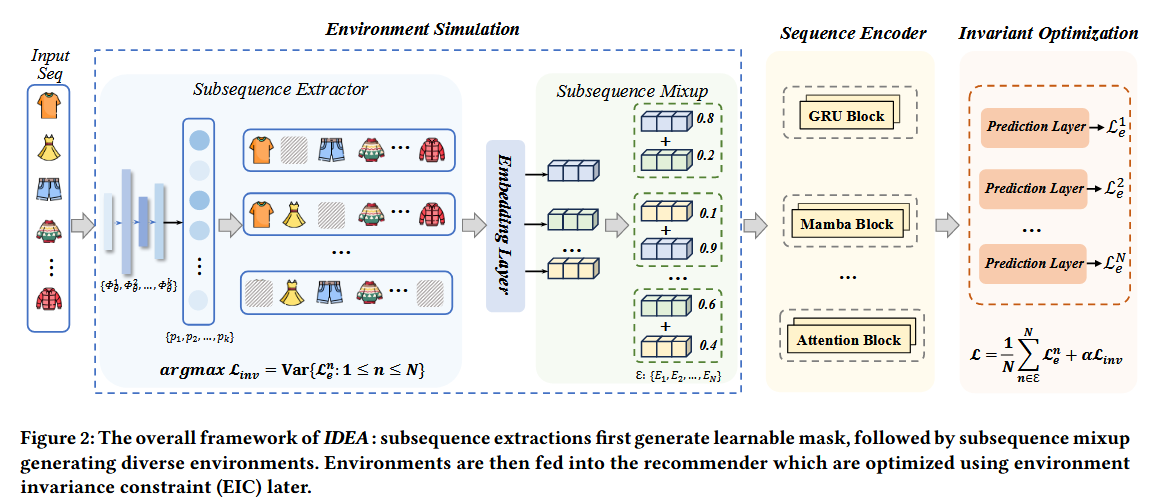
1. Environment Simulation
(1) 序列推荐模型的预训练
预训练一个基础的SR模型,以获得item embeddings; 具体实现SR基于三个代表性的backbones。
I:预训练得到的item embedding矩阵
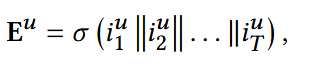
- ||: concat操作;
itu:用户u在时间戳t的item embedding;
- σ:平均池化层操作。
以Eu为作为下面subsequence extractor的输入。
(2) 子序列提取
设计了K个独立的子序列提取器
对于每个用户在前面得到的Eu, 通过一个MLP Φ:
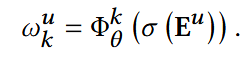
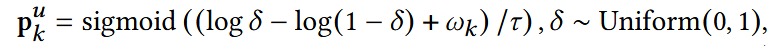
- p: 由一个伯努利分布采样,可认为是掩码向量,决定用户序列里每个位置是否保留;
- 使用Gumbel-Softmax近似伯努利采样,使得过程可导
- τ:温度系数,接近0,则输出接近0/1;较大,则输出为连续概率,更平滑;
- sigmoid映射到(0,1)空间,近似成伯努利分布的采样。
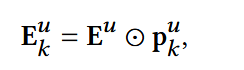
- 每个提取器得到一个新的用户表示。

(3) 子序列 mixup
来自有限训练domain的环境不足以覆盖全部的潜在domain。
环境的创建遵循:
- Interest-driven heterogeneity: 不同的环境应该被用户兴趣的不同子集主导;
- Sufficient environmental diversity: 必须模拟出一个广泛范围的环境,以增强模型的泛化能力。
使用Mixup:
随机从D1 中选择两个子序列Si, Sj; 获得他们的序列表达Ei, Ej;得到混合表达:
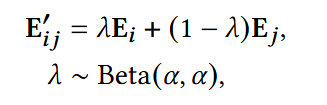
- λ:接近1
两个E可以来自不同用户,不同提取器。
Beta(α,α):对两个样本一视同仁,不偏向任意一方。
重复上面的采样过程N次,获得N个不同的环境。
包含两种兴趣,把原来分散的兴趣分布连续化了,扩展了训练环境的覆盖范围。
2. Invariance-based Optimization
Environment Exploration
理想的环境应该最大的违背不变性准则,也就是最大化模型学习稳定特征的挑战。
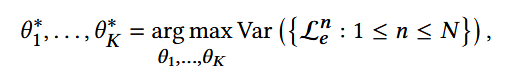
- θK : K子序列提取器的参数;
- Len: 第n个环境的BCE损失。
最大化N个环境的expirical risk的方差,以鼓励子序列提取器探索更有挑战性的环境。
这样训练时模型必须学到更稳定、更本质的特征才能在所有环境里都表现好。
该优化与后面的整体优化是交替进行的,每T个迭代是一个周期。
Overall Optimization
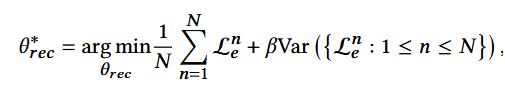
- θrec: 推荐模块的参数,也就是最开始用来获得embedding的序列推荐模块;
- 第二项:同前不变性约束部分,β为超参数。