09_Adaptive User Dynamic Interest Guidance for Generative Sequential Recommendation
来源:SIGIR‘25 https://dl.acm.org/doi/10.1145/3726302.3729888
问题的引出
- 现有模型难以捕捉用户动态兴趣,且现有模型预定义的固定兴趣数无法适应用户多样化的偏好;
- 传统判别式模型很难探索用户与未交互item之间的潜在可能性;
- 生成式模型用于推断这种可能性,但是存在拟合困难和后验坍塌等问题;
- 扩散模型,由于用户兴趣是动态且非平稳的,用历史序列直接编码出来的引导信号会带来不确定性;
- 总的来说, 在逆过程训练神经网络进行去噪时:
- MLP:确保生成item的多样性,但缺乏与引导条件的交互,导致生成结果可能出现偏差;
- Transformer: 拟合噪声是在用户偏好空间而非目标空间,限制了结果的多样性。
- 总的来说, 在逆过程训练神经网络进行去噪时:
Adaptive User Dynamic Interest Guidance for Generative Sequential Recommendation (ADIGRec)
- DIFGC (Dynamic Interest Features as Guidance Condition): 将用户动态兴趣特征和固有兴趣特征结合起来,作为显式的引导条件;
- AI2M (Adaptive Condition Insert Module): 将动态兴趣特征注入到噪声项中,以影响扩散模型的生成结果;
- 正则化方法:无需额外参数,减少user interest routing collapse的影响。
准备工作
符号表达

用户ui的交互序列表示为:
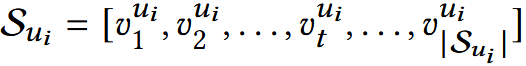
扩散模型
https://hhhi21g.github.io/posts/base01/
ADIGRec
1. Dynamic Interest Features as Guidance Condition (DIFGC)
将用户的动态兴趣特征和固有的兴趣特征整合起来作为显示的指导条件。
(1) Embedding Layer

(2) 用户兴趣特征提取
使用基于两层MLP的自注意力机制,提取权重分数矩阵:
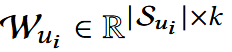
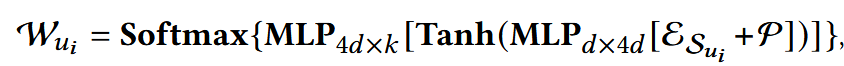
- P: position embedding;
- k: 兴趣特征的数量;
用户兴趣特征提取如下:
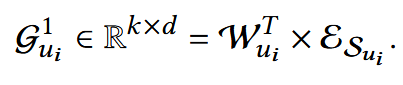
(3) 用户动态兴趣特征提取
通过两个transformer blocks, 每个block包含一个自注意力层和一个前馈层:
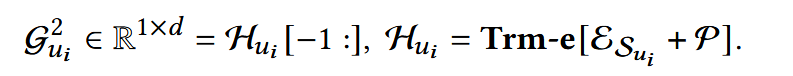
- Trm-e: Transformer Encoder
- [-1: ]: 直接去取最后一个,直觉上,最后一个item最能代表用户当前的短期兴趣\动态兴趣
(4) 生成指导条件
(2)(3)中获得用户k个固有兴趣特征和动态兴趣特征,能够被视为用户大概的长期兴趣和短期兴趣,他们有效的结合能够构建用户真实的交互偏好。
利用这一特征,模型能够在目标物品的噪声空间,被引导生成真实的用户偏好表示。
为保持两个特征的独立性同时丰富指导信息,做concat得到最终指导条件:
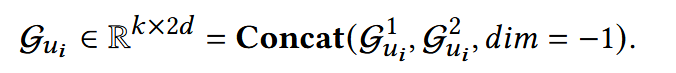
噪声项和时间步t沿着特征维度拼接到高维空间,再映射回预测空间。
2. Adaptive Condition Insert Module (AI2M)
为了解决扩散模型在去噪过程的限制,提出该模块:
向目标噪声embedding中,动态注入指导条件Gui , 通过cross-attention机制加强指导强度。
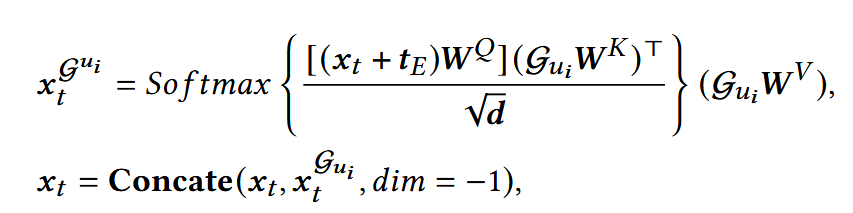
WQ ∈ Rd×d, WK ∈ R2d×d, WV ∈ R2d×d :可训练参数;
tE: 时间步t的embedding。
直接用一个embedding矩阵,把t当作索引,查出对应向量,然后和其他输入一起训练更新。
xt: 反向去噪过程中,输入模型的,包含噪声的物品item.
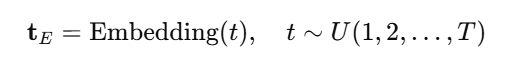
3. 训练扩散模型
(1) 训练阶段
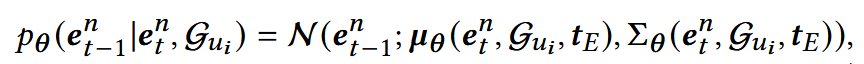
- μ:通过一个可训练的单层MLP fθ进行预测;
- n = |Su + 1|;
- e就是前面的x
重采样μ:
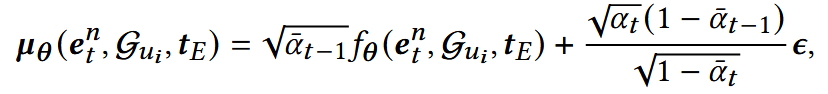
优化目标:
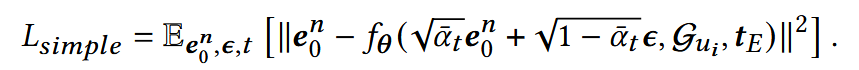
(2) 在学习阶段的新策略
为了减少指导条件可能造成的路由坍塌的影响,设计一个正则损失。
计算权重分数矩阵的协方差:
Euclidean distance (欧几里得):
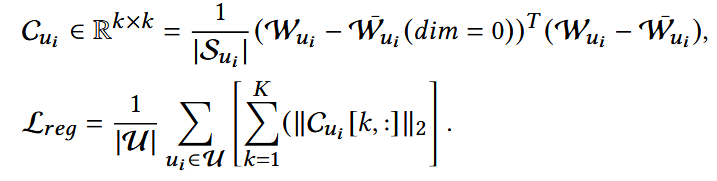
平方项:协方差矩阵第k行的平方和,里面包含了兴趣k与所有其他兴趣的协方差;
如果兴趣k与其他兴趣高度相关,行向量里的元素会很大,范数也会大;
因此优化它,能够使兴趣之间相关性变小,避免坍塌成一个。
4. 损失函数
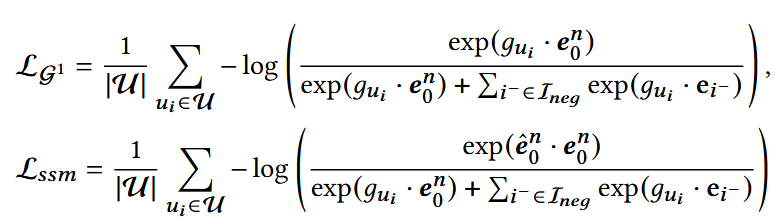
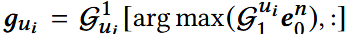
- e0n: 目标item的embedding;
- e_hatnn: f(θ)的预测结果。
整体优化损失:
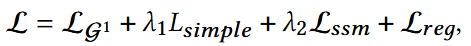
整体算法流程:

- L2归一化,把embedding映射到单位球面上,来自DimeRec, 避免embedding尺度不一致,让训练更稳定,同时更好的对齐兴趣特征。也就是将e拉到球面上,使它的范数为1;
ADIGRec的生成阶段
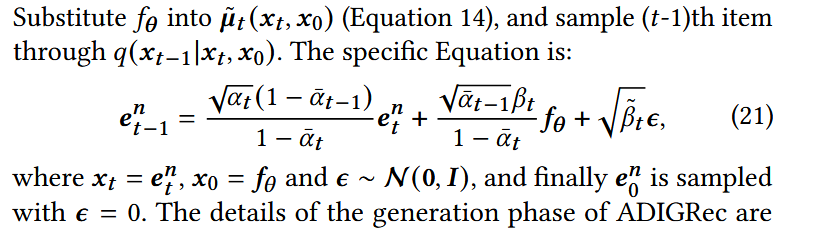
整体生成算法流程:
