10_Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
10_Data Augmentation as Free Lunch: Exploring the Test-Time Augmentation for Sequential Recommendation
来源:SIGIR‘25 https://arxiv.org/abs/2504.04843
代码:https://github.com/KingGugu/TTA4SR
问题的引出
- 现有的数据增强方法在模型训练过程中生成数据,使用他们需要重新训练、改动结构或引入额外的可学习参数;
- 启发式方法(heurisitc): 引入更差质量的数据,有时甚至干扰模型表现;
- 基于模型的数据增强方法(反事实增强,扩散模型,双向Transforer):需要专门的数据增强模块。
由此引出,使用TTA则不需要重新训练或改变原始的模型结构
结论:
- 测试当现有数据增强方法被用于TTA的表现:
- Mask (额外引入无效信息,削弱最终推荐效果) (一般为第二好)和Substitute (选择相似item需要高的计算和时间花费) 最好;
- 它们能够在保留原始序列模式的同时引入正确的扰动:
- Mask增强数据与原始数据相似度最高,Substitute第二高
- 使用大语言模型获得原始序列的关键交互部分,基于结果研究数据增强进行的位置的影响:
- 随机选择最好: 由于关键词只占一小部分,对于TTTA的恰当选择应该是,一小部分关键交互和一大部分非关键交互。
由此提出两个TTA方法:
- TNoise: 向原始表示注入均匀噪音;
- TMask: 屏蔽掉mask token的embedding,或直接去掉mask位置对应的交互。
准备工作
1. 序列数据增强方法
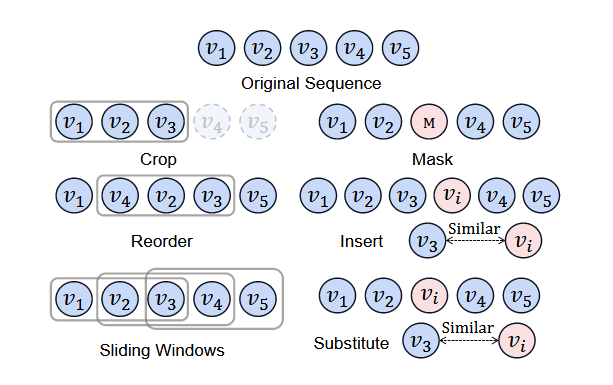
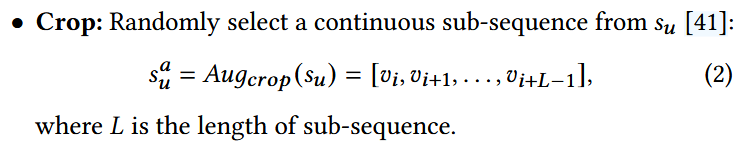
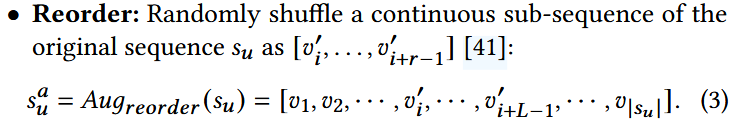
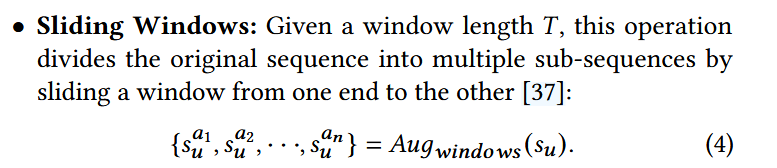
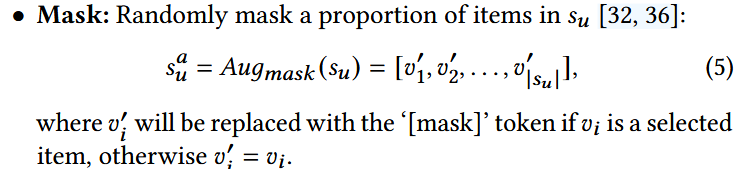

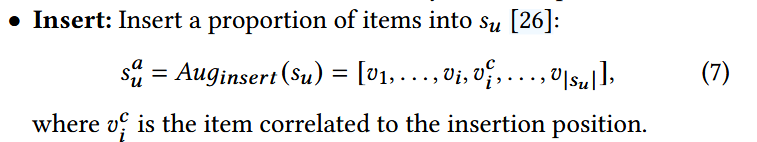
2. Test-time Augmentation(TTA)
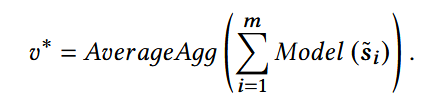
- si_~: 第i个增强序列;
- m: 增强序列的总数;
- 对不同的增强序列的预测结果取平均值,得到最终的预测结果。
TNoise and TMask
Mask和Substitute存在不足:
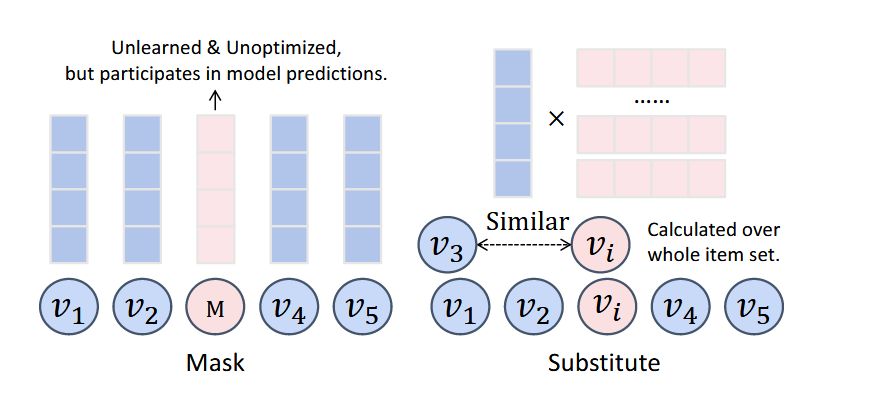
由此提出:
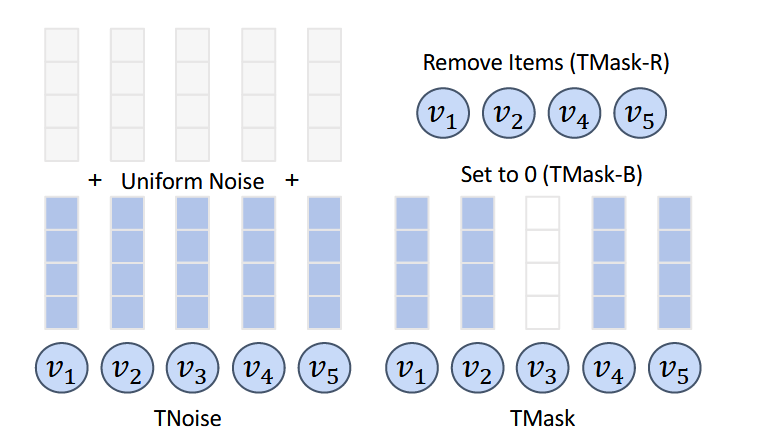
TNoise
直接向序列表示添加均匀噪音。
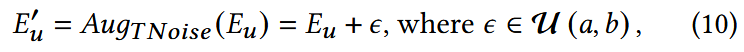
- Eu:交互序列的embedding;
- a,b:超参数,控制噪声的方差。
同样可用于序列的隐藏状态:
将E输入Encoder,获得序列的隐藏状态Hu,同样可通过上式获得Hu‘。
a=1,b=0.5性能较好。
TMask
使用原始Mask时,模型被不能学习、不能优化的Mask token所影响。
(1) TMask-B
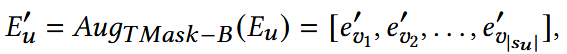
- 如果evi被选择,则相应的evi‘会被置为0; 否则保持不变。
(2) TMask-R
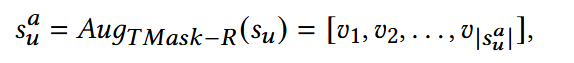
- 如果evi被选择,则相应的evi‘会被删除;
- sua: 删除后的序列;
- 对于序列长度为L的学列,被操作的item应为Lσ个,σ∈(0,1)为超参数。
可能的限制
- 现有TTA能够带来的提高比训练时增强低:
- 训练时增强在训练过程能提供更多数据,并且帮助模型更好的学习用户的偏好和序列模式;
- 可能将TTA和训练时增强结合能够得到更好的表现;
- 有些研究表明,TTA在特定模型和特定方法下会失效。
This post is licensed under CC BY 4.0 by the author.