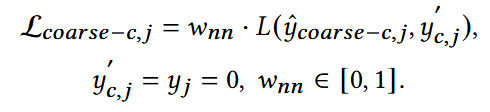11_MGIPF:Multi-Granularity Interest Prediction Framework for Personalized Recommendation
来源:SIGIR‘25 https://dl.acm.org/doi/pdf/10.1145/3726302.3730033
代码:https://github.com/GeWu-Lab/MGIPF
问题的引出
现有方法建模用户偏好通过拟合细粒度标签(如,点击行为),但常常忽略了粗粒度的兴趣信息。
- 细粒度的信息可能携带不可避免的噪音;
- 在数据方面要求相当高,对于现有的方法能够有效建模用户的多粒度兴趣,通过有限或不足以支撑的样本(必需大量样本以确保满意的表现);进而引起长尾效应的不佳表现。
共识:
- 用户的兴趣展现在粗粒度物品特征的不同层次,如一个特定的种类或品牌;
研究得到:
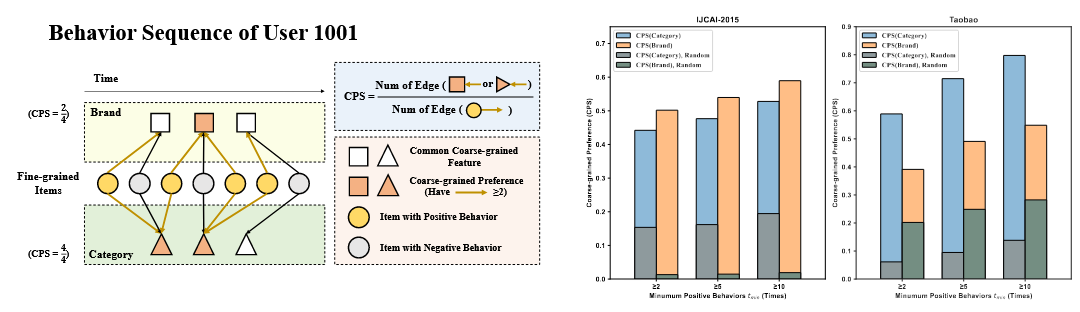
- 对于有两个及以上有效交互的用户,对于一个特定品牌或种类出现循环行为的概率非常高;
- 正标签能反映用户在粗粒度item上的兴趣。
黄线:存在交互行为;
黑线:不存在交互行为。
由右图可知,用户对于特定种类或品牌的CPS远高于随机情况的CPS。
CPS:用户对于某一种类或品牌的(有2次及以上交互才算)交互在所有交互中的比例。
因此提出:
Multi-Granularity Interest Prediction Framework(MGIPF)
- 细粒度预测模型:使用传统的推荐模型,对于在特定item上的复杂兴趣预测;
- 粗粒度预测模型:在高层次预测用户兴趣;
- 提出一种soft coarse-grained损失,为每个样本的粗粒度损失分配一个样本级别的权重。
MGIPF
1. 符号说明
U = {u1, u2, …, uM }
I = {i1, i2, …, iN }
粗粒度特征namespace: C = {Brand,Category,…}
每个item有Q个粗粒度:
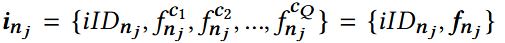
- iID: 第j个记录的细粒度item ID;
- f: 粗粒度item特征
每条数据集中的记录可表示为:{inj, umj, yj}, 其中yi为标签
2. 对于多粒度兴趣的伪标签
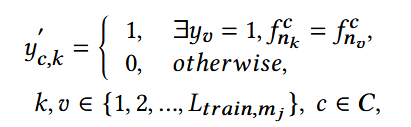
- 对于用户umj, 获得第k个item在粗粒度特征c上的伪标签;
- 去找该用户交互的item中,同样包含该粗粒度特征c的交互:
- 如果找到的交互标签为1,则把该第k个item的伪标签也置为1;否则为0.
使正标签多很多,像正标签的传递
粗粒度伪标签用于解决训练标签噪声问题
用户可能对一些推荐感兴趣,但是没有展现出正行为(由于广告的放置等)。使得细粒度标签的分布与真实的分布不同。
设置一个粗粒度标签 ycoarse,能够覆盖一些细粒度标签在负样本上的噪音,这些粗粒度标签同样包含噪音。
用户的喜好可以被分为3类:
- Full Interest (FI): yfine,j = ycoarse,j = 1
- Partial Interest (PI): yfine,j = 0, ycoarse,j = 1
- No Interest (NI): yfine,j = ycoarse,j = 0
推导与结论:
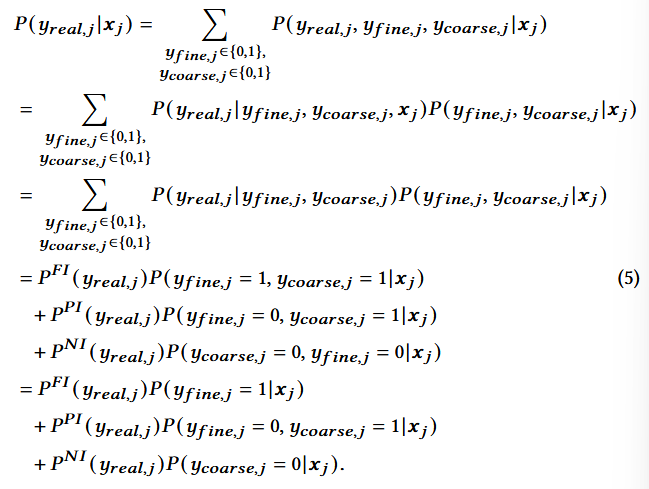
- 第一步:概率论技巧,引入因变量做分解,对隐变量b的所有可能取值做求和,等于把b边缘掉;
- 第二步:链式法则,P(A,B|C) = P(A|B,C)·P(B|C);
- 第三步:条件独立假设,把条件xj从第一个概率里去掉;也就是,已知yfine和ycoarse,原始特征xj即使不提供也能够知道真实标签。
- ycoarse即前面得到的伪标签;yfine也就是训练标签;
- 由上式可知,如果用户对一个商品感兴趣但是没有表现出来:
- 该项的粗粒度标签为1,而此时是PI,会被上式的第2项修正,标签为1而非0.
3. 多粒度的兴趣预测框架
(1) 细粒度兴趣预测模型
先获得embedding矩阵E;
将E输入进堆叠的交互模块:
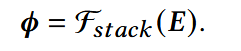
获得特征间的交互表示φ。
细粒度预测模型Ffine,用来学习高阶的特征交互,输出对于细粒度物品兴趣预测的表示;
依赖于具体的推荐模型骨干
并行交互模块Fparal, 增强表示能力,避免单一模块可能的不足。
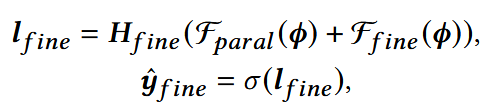
- Hfine: 预测头;
- σ:Sigmoid激活。
大多数主流的推荐模型,实际上只包含一个并行或堆叠的特征交互模块;而另一个模块如果没有,就直接不起作用,相当于直接输入输出。
损失函数:
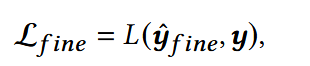
(2) 粗粒度兴趣预测模型:预测用户对于粗粒度特征的潜在兴趣
对于每个粗粒度特征,有一个相似但独立的粗粒度预测模型Fcoarse;
与细粒度兴趣预测模型共享embedding层和交互模块;
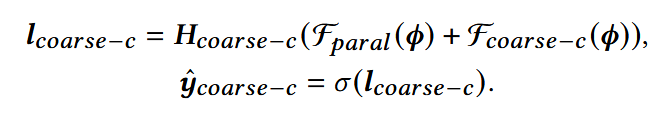
损失函数:使用前面获得的伪标签
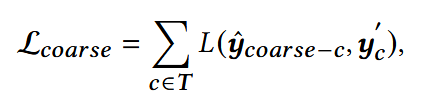
T为粗粒度特征的集合。
(3) 最终预测层
整合前面两个模型的预测结果,并作出最终的行为预测。
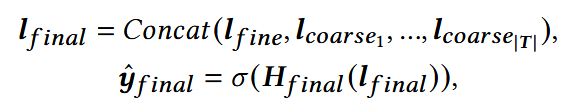
- Hfinal: 权重头
损失函数:
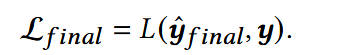
整合各个模块的损失,得到总体损失函数:
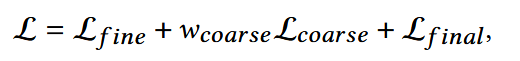
- wcoarse:超参数
4. Soft Coarse-Grained Loss
伪标签可能携带噪声,同样分三种情况讨论, 添加样本级权重:
(1) Full Interest: 权重=1
用户确实交互了商品,并且在粗特征上也有兴趣。因此在正样本上几乎没有噪声,无需调整权重。
**(2) Partial Interest: **权重<1
用户没点某一确定item,但在对应的品牌上有兴趣:用户可能有潜在兴趣,只是没点;
伪标签能够减少一定该噪音,但伪标签本身可能过于宽泛(用户喜欢某一品类,但不是喜欢该品类所有商品),可能使负样本误认为正样本。
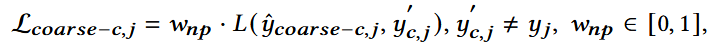
(3) No Interest: 权重<1
基本是真负样本,但粗颗粒标签本身可能有噪声:用户没有点击过某个品牌,但不代表一定不喜欢;
存在将正样本误认为负样本的噪声。