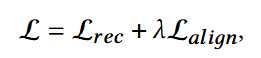12_DIFF:Dual Side-Information Filtering and Fusion for Sequential Recommendation
来源:SIGIR‘25 https://arxiv.org/abs/2505.13974
代码:https://github.com/HyeYoung1218/DIFF
问题的引出
Side-information Integrated Sequential Recommendation(SISR): 对于稀疏交互和冷启动序列是有效的,其分为三类:
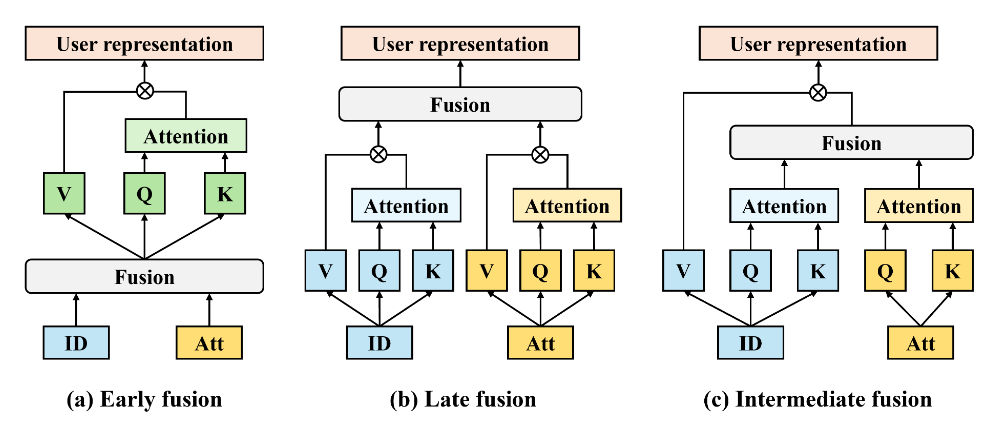
- early fusion: 将ID和属性在放入模型前就结合;
- 融合后的信息可能被ID或属性信息所主导。
- late fusion: 最终预测层将二者融合;
- 难以捕捉ID和属性之间的联系。
- intermediate fusion: 整合受关注的属性进ID,给相应item分配更高的注意力分数。
但存在下面的问题:
- 没能移除噪音信号:item序列存在意外点击、短期兴趣偏移等噪声;现存方法利用所有可用的信息以推断用户兴趣,噪声可能引起对于真实用户偏好预测的偏移;
- 没有充分利用辅助信息:主要利用属性指导ID,没有直接将属性整合进用户表示。
Dual Side-Information Filtering and Fusion model (DIFF)
- Frequency-based Noise Filtering: 使用离散傅里叶变换将序列转为频域信号,对于每个序列应用属性级别的过滤;
- Dual Multi-sequence Fusion:
- ID-centric Fusion (intermediate): 捕捉属性内的相关性;
- Attribute-enriched Fusion (early): 捕捉不同属性间的相关性。
准备工作
1. 符号表示
item集合:I = {i1, . . . , in }
用户物品序列:s = [i1, . . . , i |s| ]
每个item i包含它独特的ID和多个属性,表示为ij = {vj, a1,j, … , am,j}
- vj:item ID;
- ak,j: 第k个属性类别;m为属性总数
2. Discrete Fourier Transform(DFT)
DFT: 将一个序列由时间域转为频率域,表示为:F : RN → CN
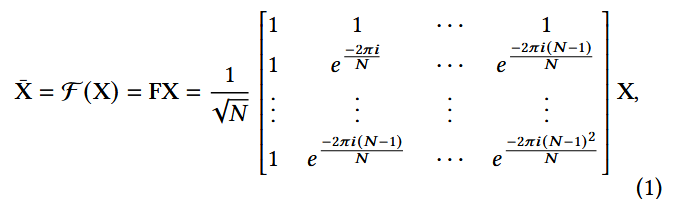
- i: 虚数单位(imaginary unit);
- 得到序列X的频率成分。
结果可被分为两部分:低频成分和高频成分
前c行:低频成分
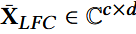
剩余:高频成分
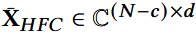
相反,inverse discrete Fourier transform(IDFT), 表示为:F-1 : CN → RN
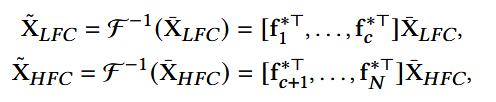
- fi: F的第i行;
- *:共轭操作;
- XLFC ∈ RN×d: 捕捉序列的总体趋势,表示不经常改变的信号;
- XHFC ∈ RN×d:有剧烈变化的信号。
DIFF
1. Frequency-based Noise Filtering
分别获得ID序列和属性序列的embedding矩阵:
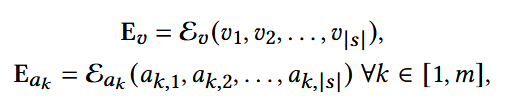
进行早期融合: 融合函数可选为相加、拼接、门控机制等。
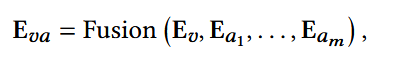
Frequency-based Filtering:
使用离散傅里叶变换,将序列投影至频域,并相应获得低频成分和高频成分:
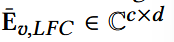
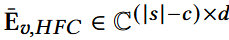
做逆变换:
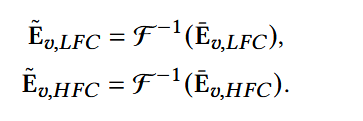
对于属性embedding和融合embedding做相同操作:
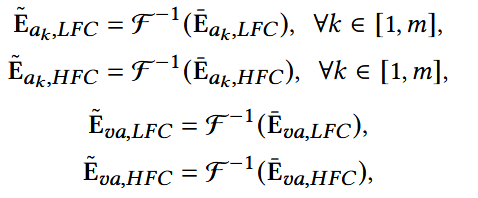
低频信号:代表在一个序列内很少变化的稳定模式(长期且一致的兴趣):关键
高频信号:信号出现快速的扰动(短期且不稳定的兴趣):可能不重要且有噪声
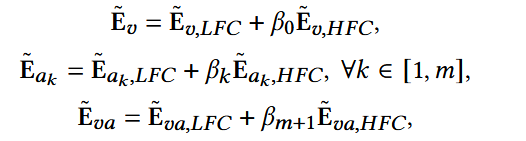
- β:可训练参数,用于调整每个embedding中高频的比例;
实验表明,β会被训练为很小
2. Dual Multi-sequence Fusion
(1) ID-centric Fusion: 捕捉ID间的相关性,中间融合
将ID和属性embedding投影至不同query和key
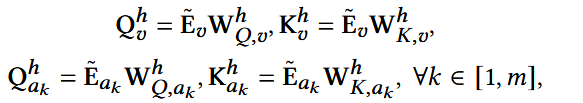
- h: 第h个注意力头
计算注意力得分:
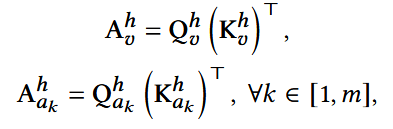
融合ID和属性的相关性,这里也就是注意力得分矩阵:
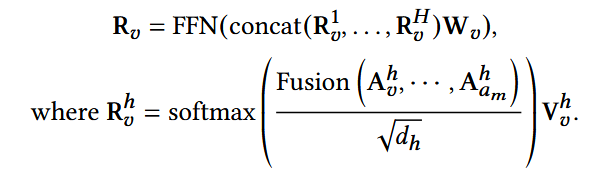
H: 注意力头数目;
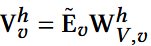
- FFN: 前馈神经网络
(2) Attribute-enriched Fusion
早期融合,对融合后的embedding使用自注意力:
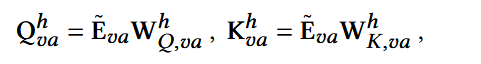
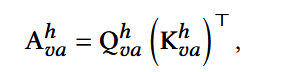
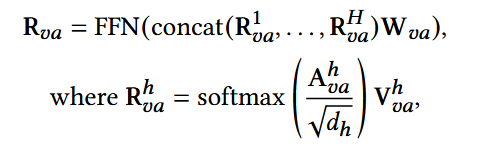
(3) 用户表示:
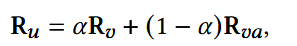
- α:超参数;
- Ru的最后一项ru,|s|:被用作用户表示向量,用于预测
3. 表示对齐
使用一个对比性损失去对齐ID和属性的embedding空间
计算ID和融合属性embedding之间的相似性:
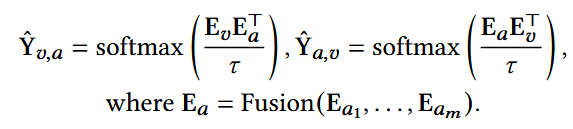
Ea: 属性的融合矩阵,这里使用求和,将所有属性的embedding矩阵逐元素相加;
τ:可学习温度系数,用于缩放。
最终对齐损失:
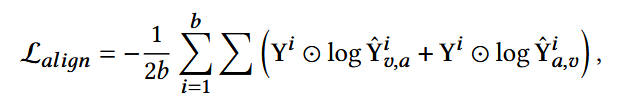
当Y=1时,让属性和ID相似度向更大的方向优化,实际优化embedding矩阵;
Y的定义:在第i个序列中,如果有两个item在属性上的embedding一致,则把该两个item的Y标为1
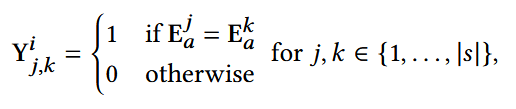
4. 训练与推断
使用最终用户表示向量和ID embedding进行预测:
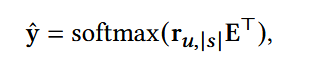
使用交叉熵损失函数:
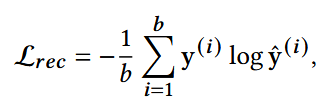
结合后的损失:λ为超参数