base01_Diffusion Models
CLIP(Contrastive Langugae Image Pre-training)
由两个模型组成,一个处理文本,一个处理图像
中心思想:给定图像及其标题的向量应该相似
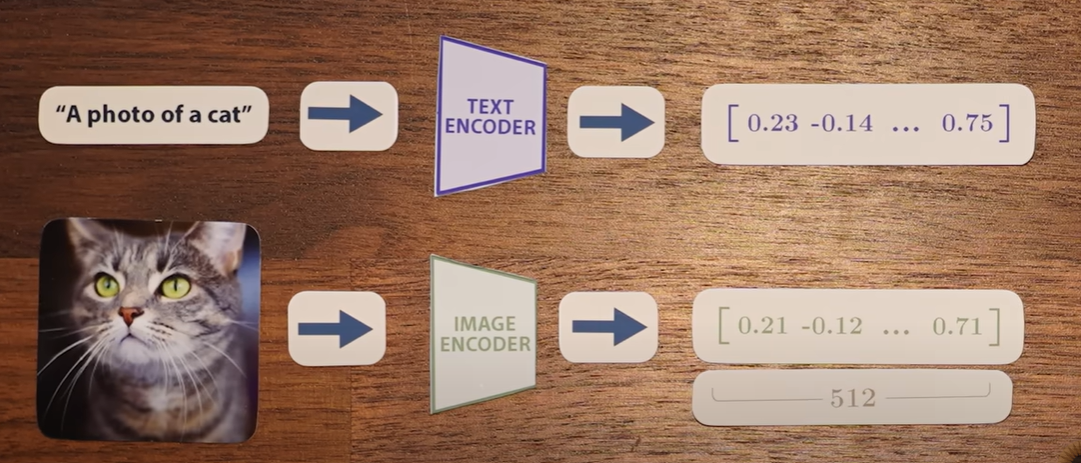
给定一批图片-标题对,利用所有对,最大化对应图片标题对之间的相似性,同时最小化非对应图片标题对之间的相似性, 使用余弦相似度来衡量向量之间的相似性。

以人像为例,一个人像戴帽子而一个不带,戴帽子的人像向量 - 未带帽子的人像向量,得到的差向量,与其最接近的匹配词也可以得到hat
CLIP只能将图片和文本映射为嵌入向量,但无法通过向量生成图片或文本。
Diffusion Models
Denoising Diffusion Probabilistic Models, DDPM

获取一组训练图片,在每张图像上逐步添加噪声,直到图像被完全破坏;
训练神经网络逆转这一过程:直接预测添加的总噪声,也就是要求模型跳过所有中间步骤,对原始图像进行预测。
在图像训练过程和生成过程都添加了噪声;
在生成新图像时,每一步都需要在神经网络预测出噪点较少的图像后,向该图像添加随机噪点(越后面添加的越小),再将其传回模型。
数学表达
1. 图像:起始图像、未加噪声x0, 完全为高斯噪声xT
2. 前向过程:
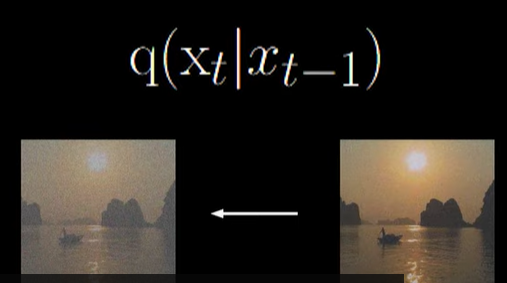
(1) 前向的正态分布
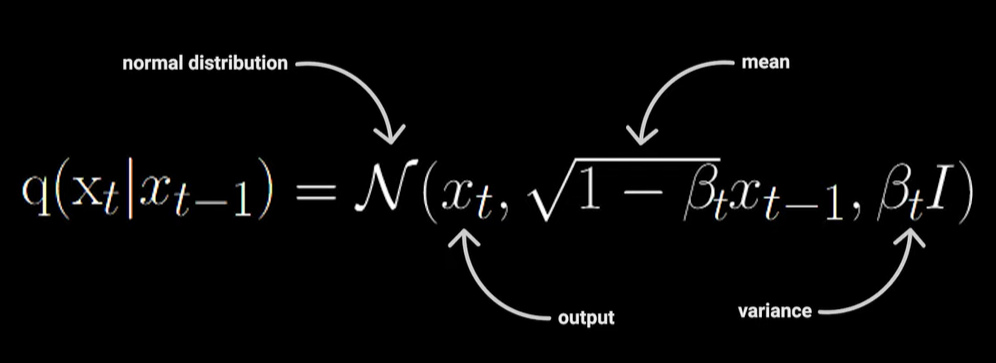
- β:随着时间缩放,为线性或余弦,0~1;
(2) 重采样
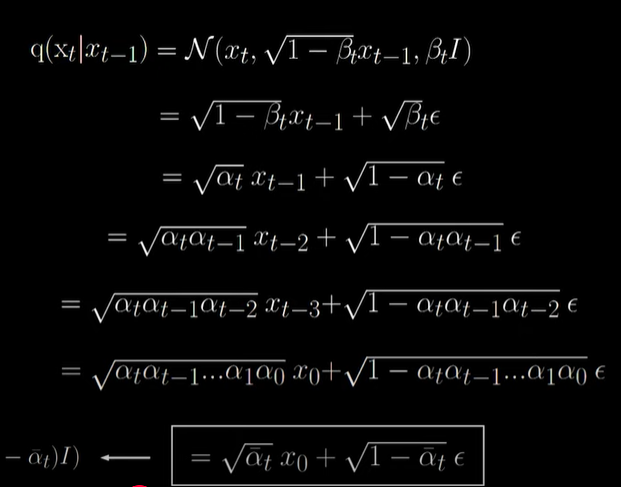
高斯噪声项说明:

β:控制每一步加入噪声的量,β越大,噪声量越多。可理解为,正态分布峰值变低,范围更大,被拉伸。DDPM规定β为线性增长:

α = 1- β,意味着图片有多少信息;
3. 逆向过程:

- μ通过神经网络进行预测;
- Σ固定;
- 目的:学习噪音
4. 优化目标

- ε:真实噪音;
- εθ: 通过模型预测的噪音;
- 平方误差
可视化理解
以一个时变向量场进行理解:
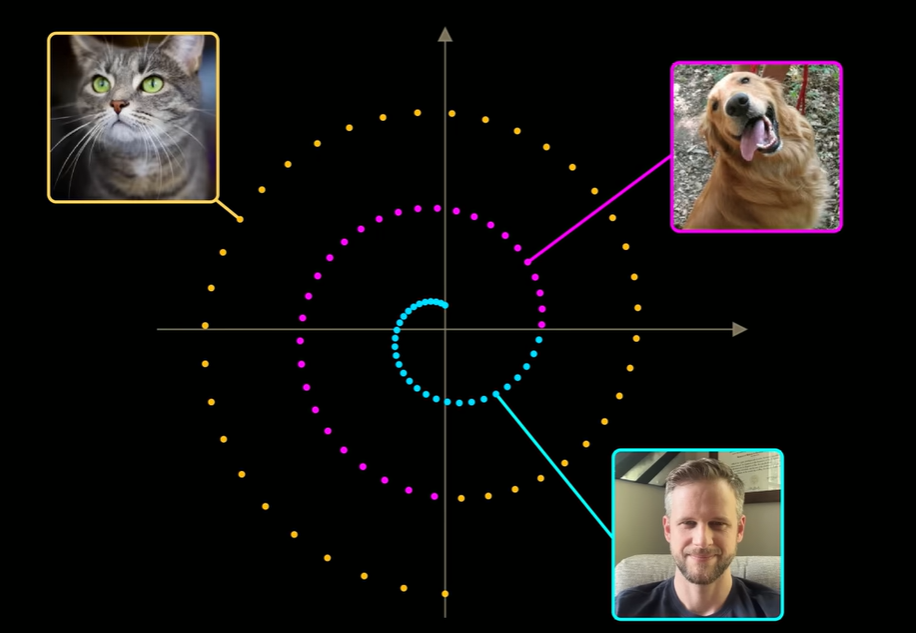
将图像视为高维空间中的一个点,每个像素的强度值控制着该点在每个维度中的位置;
如果图像只有两个像素,就可以在散点图的x轴绘制第一个像素的像素强度值,在y轴绘制第二个像素的像素强度值:
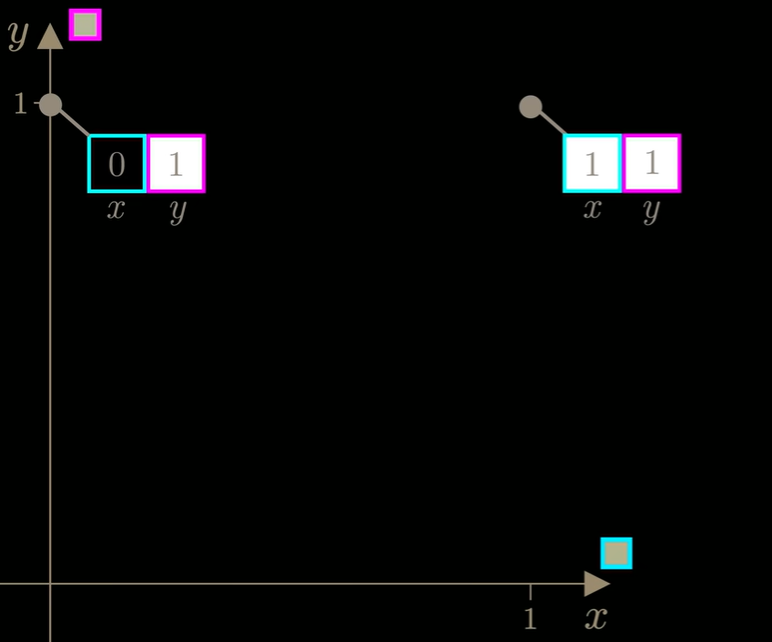
当添加随机噪声时,实际是在随机改变每个像素的值,也就是相当于向随机选择的方向迈出一步。
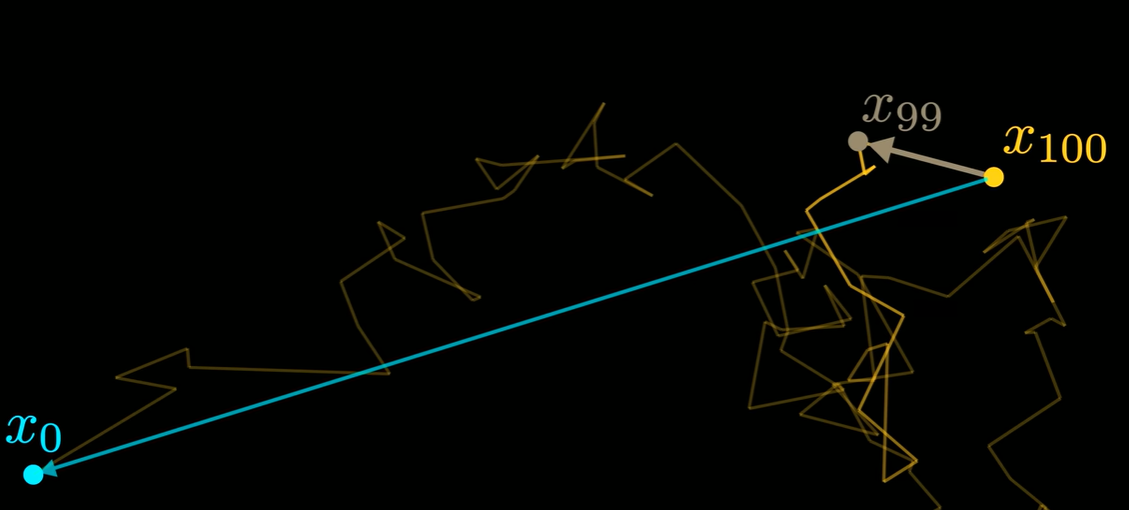
- 期望模型最终学会指向起点
以一个点的邻域为例,过程中会有很多点经过这个邻域,而他们都是由起点扩散出来的,以此学习该点指向起点的向量。

- 模型在t值较大,也就是离起点更远时,只学习粗略的向量场;而在t接近0,学习精细的方向。
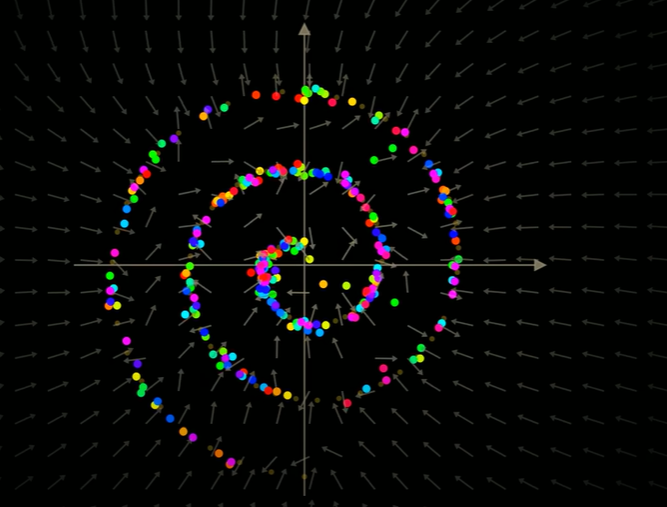
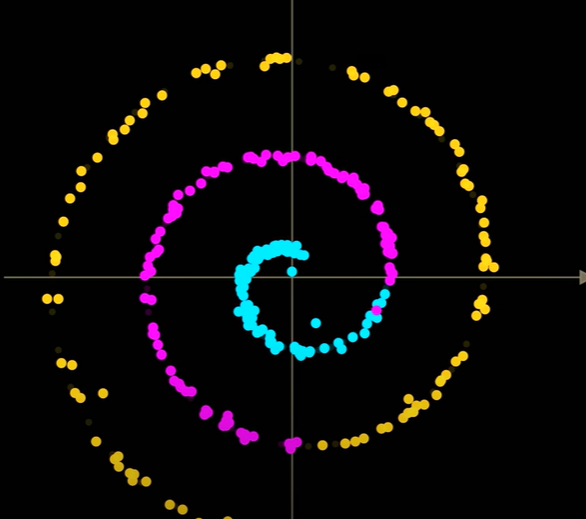
- 使用DDPM能够很好的使得随机点回到起始位置
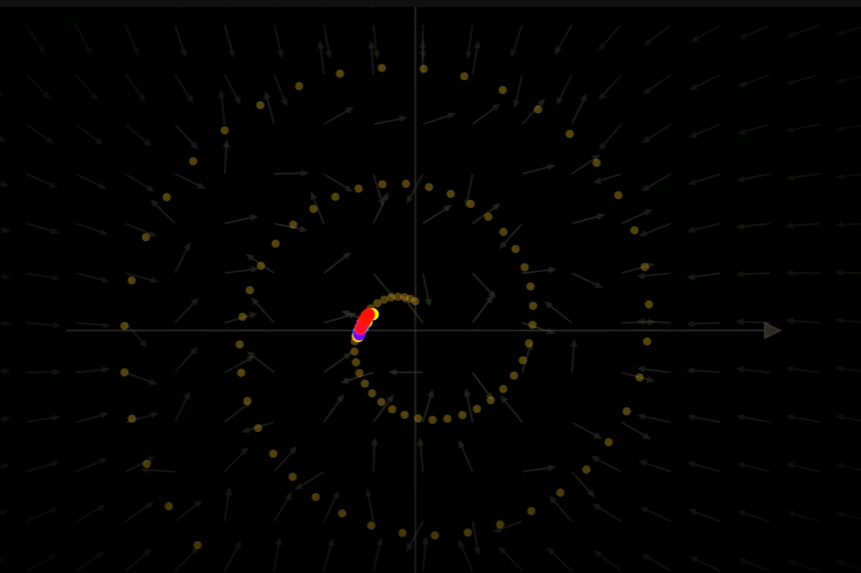
- 如果生成过程中不添加噪声,则会快速聚集到一处,最终都接近螺旋的中心或平均值,在真实的图像高维空间中,会导致模糊的非现实图像。
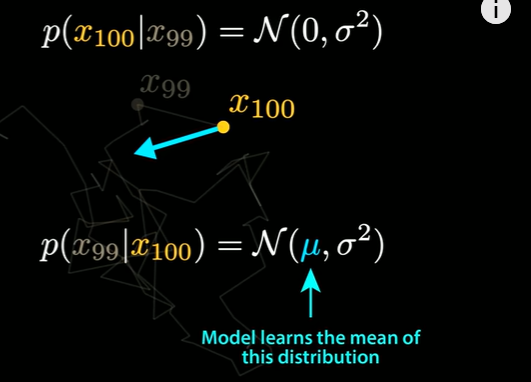
- 如果在正向过程中添加的噪声是高斯分布,那么在步长足够小的情况下,反向过程也将遵循高斯分布,而模型实际上学习到的将是这一分布的均值。
因此要真正的从该分布中采样,需要在模型预测值上添加0平均高斯噪声
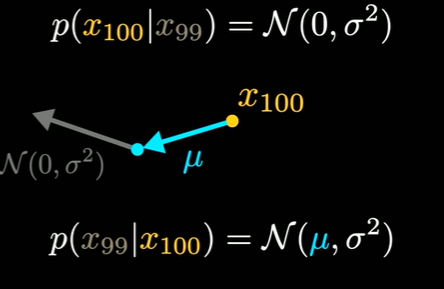
DDPM生成高质量图像所需的大量步骤对计算能力要求很高,因为每一步都需要完整的通过一个可能非常庞大的神经网络。
Denosing Diffusion Implicit Models(DDIM)
每个点的运动遵循如下随机微分方程:
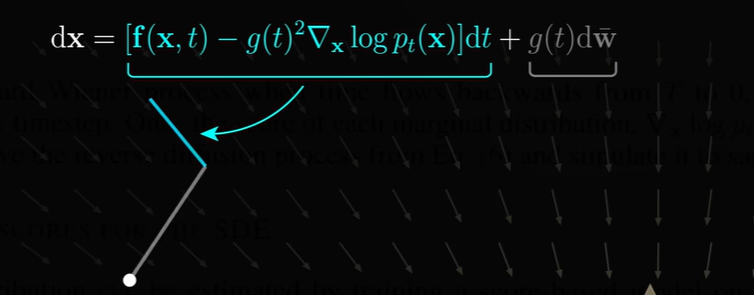
- 第一项:模型矢量场驱动的点的运动;
- 第二项:点的随机运动。
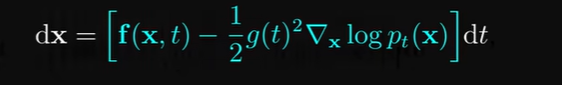
一个没有随机成分的常微分方程,其最终的点的分布与随机微分方程完全相同;
利用模型学习到的矢量场生成图像,沿途无需采用随机步骤,一般称为DDIM。

二者添加噪声的步长不同
DDIM步长缩放更小,使得轨迹能够更好地跟随矢量场的轮廓线,并很好的落到正确的螺旋分布上。
使用文本提示引导传播过程的能力非常有限
DALI2(unCLIP)
扩散模型有可能逆转CLIP图像编码器,生成高质量图像,而CLIP文本编码器的输出向量可用来知道扩散模型向想要的图像或视频发展。
将提示输入CLIP文本编码器,生成一个嵌入向量,使用该嵌入向量将扩散过程导向提示所描述的图像或视频
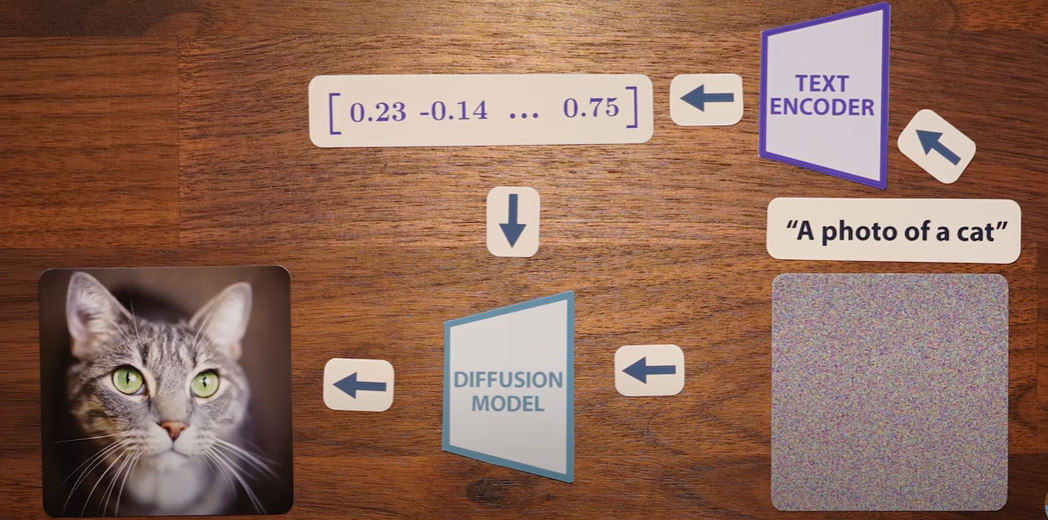
将文本向量输入到扩散模型中,向通常一样进行训练以去除图片噪音
使用图像和标题对来训练扩散模型
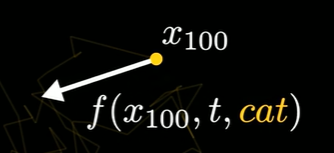
- 要求不只要输入起始坐标和扩散时间,还要输入点的类别
实际上可能造成一定混淆
要求模型同时学会指向现实图像的整体螺旋,以及螺旋上的特定类别;
总体上与整体螺旋相匹配的建模任务,已经压倒了模型向特定类别方向移动我们的点的能力。
利用未针对特定类别训练的无条件模型与针对特定类别训练的有条件模型之间的差异
不向模型传递任何类或文本信息,得到一个指向一般数据而非任何特定类的矢量场。
- 当扩散时间较大时,两个矢量场基本指向一个方向,大致即为螺旋的平均值
- 时间趋于0时,矢量场就会发散,猫条件矢量场则会更多的指向螺旋的外部猫的部分。
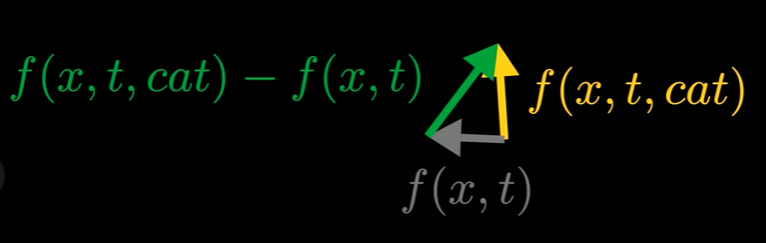
- 作差,既然已经移除了一般指向数据的方向,那么这个差方向应该更多指向猫
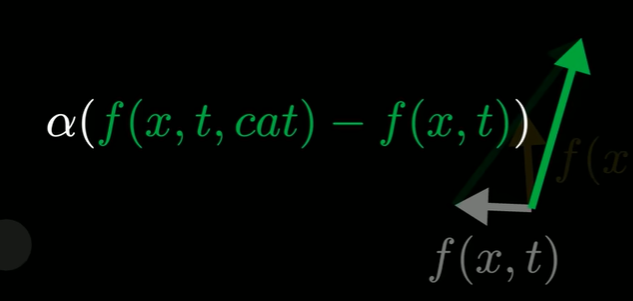
- 通过乘以缩放因子alpha放大这个方向,并用指向这个新方向的矢量来替代原来的条件黄色矢量
WAN:并没有减去没有文本输入的无条件模型的输出,而是使用了所谓“负面评价”,即在视频中特别写出他们不希望出现的所有特征。
视频教程:
https://www.youtube.com/watch?v=iv-5mZ_9CPY&t=2032s
https://www.youtube.com/watch?v=iv-5mZ_9CPY&t=2032s
https://www.youtube.com/watch?v=0bRX0FNsRao